Big Data Compute Edition w Oracle Cloud - część 2
Tworzenie klastra obliczeniowego na infrastrukturze Oracle (część 2)
Korzystamy z burger-menu (lewy górny róg strony).

Wybieramy kolejno (tak jak na rysunku poniżej)
Burger Menu zakładka Solutions Platform and Edge My Service Dashboard
Zostaniemy przekierowani na inny interfejs graficzny podobny do tego
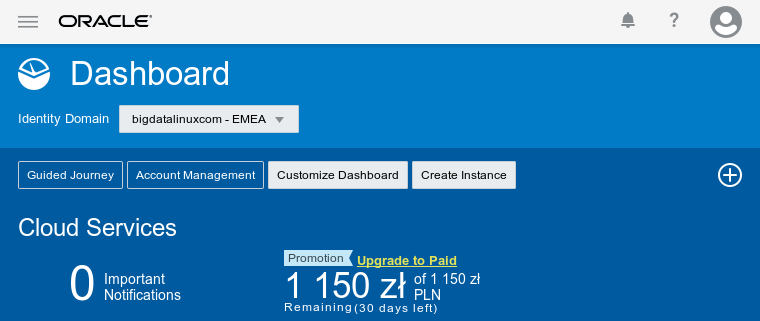
W lewym górnym rogu jest Burger Menu w którym kolejno wybieramy
Kolejno Services i Big Data Compute Edition.
W zakładce Instances mamy pomoc (linki do materiałów) oraz możliwość utworzenia klastra Big Data opartego o Apache Hadoop i rozwiązania Oracle.

Tworzymy klaster za pomocą Create Instance.
Konfiguracja regionu
Mamy formularz do uzupełnienia
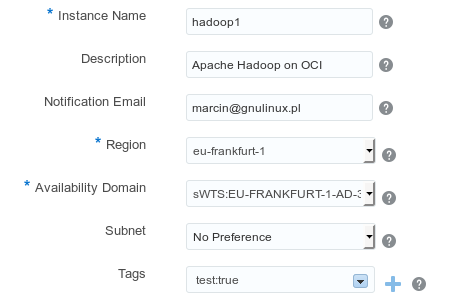
Instance Name: hadoop1
- Nazwa klastra
- Nazwa z maksymalnie 50 znaków
- Tylko litery i cyfry
- Rozpoczynamy tylko od litery
Description: Apache Hadoop on OCI
- Opis / komentarz
- Przydatna przy dużej ilości usług
Notification Email: wpisujesz Swojego maila
- Na ten adres przychodzą powiadomienia zmiany statusu usługi
Region: eu-frankfurt-1
- Miejsce tworzenia naszej instancji
Availability Domain: sWTS:EU-FRANKFURT-1-AD-3
- Rejon wraz z Availability Domain
Subnet: No Preference
- Przy takim wyborze podsieć zostanie nadana automatycznie
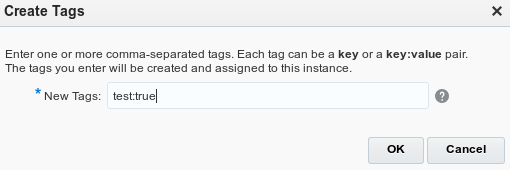
Tags: test:true
- Parametr opcjonalny
- Pomaga w strukturze wielu usług
Przechodzimy do kolejnego ekranu za pomocą Next
Konfiguracja zasobów klastra
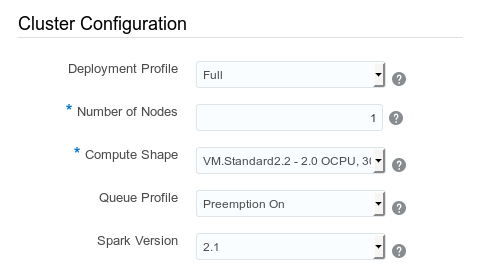
Deployment Profile: Full
- Profil na jakim uruchamiamy klaster (niżej)
- Full dla Spark, MapReduce, Zeppelin, Hive, Spark Thrift, Big Data File System
- Basic dla Spark, MapReduce, Zeppelin
- Snap dla Snap, Spark, Zeppelin
Number of Nodes: 1
- Ustawiamy z ilu węzłów ma się składać klaster
- Na potrzeby tego ćwiczenia ustawiamy jedną instancję (wszystkie usługi będą znajdować się na tej samej maszynie)
- Dla zrobienia HA wymagana minimalna wartość to 3
- Wartość maksymalna: 100
Compute Shape: VM.Standard2.2 - 2.0 OCPU, 30.0 GB RAM
- Wskazuje moc zastosowanych węzłów
- Dla dużych środowisk / zwiększenia wydajności dysku, sieci, CPU wybieramy wyższe parametry
Queue Profile: Preemption On
- Wskazujemy kolejki zadań dla różnych typów obciążeń
- Każda kolejka ma gwarantowaną minimalną wartość obciążenia
- 3 kolejki -
Preemption On - 2 kolejki -
Preemption Off - Kolejki zmieniamy w panelu zarządzania
Preemption On - opis kolejek:
- api (min: 50, max: 100)
- interaktywna (min: 40, max: 100)
- domyślna (min: 10, max: 100)
Preemption Off - opis kolejek:
- dedykowana (min: 80, max: 80)
- domyślna (min: 20, max: 20)
Spark Version: 2.1
- Wersja platformy Apache Spark do zainstalowania
- ostatnie wydanie: listopad 2016 -
1.6 - ostatnie wydanie: czerwiec 2018 -
2.1
Dostęp do klastra dla użytkownika - dla nas
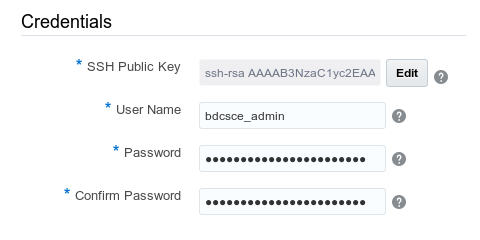
SSH Public Key: ssh-rsa xxxxxx...
Mamy 3 możliwości dodania dostępu do węzłów
-
Key File Namewskazujemy plik z naszym kluczem publicznym
-
Key Valuewklejamy jego zawartość
-
Create a New Keyusługodawca generuje dla nas parę kluczy i otrzymujemy klucz prywatny
User Name: bdcsce_admin
- Nazwa użytkownika dla konsoli Big Data Cloud i API REST
- Nazwa użytkownika admin nie jest dozwolona
Password, Confirm Password: nASZe7hasło_@_fuN_GNU_tuX
- Minimalnie 8 znaków
- Minimum jedna mała i wielka litera
- wymagana przynajmniej jedna cyfra
Konfiguracja przestrzeni do magazynowania danych
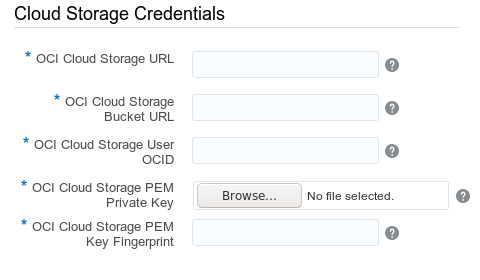
OCI Cloud Storage URL: https://objectstorage.eu-frankfurt-1.oraclecloud.com/
OCI Cloud Storage Bucket URL: oci://oraclebigdata@bigdatalinuxcom/
OCI Cloud Storage User OCID: ocid1.user.oc1..aaaaaaaafxxx ... xxx
OCI Cloud Storage PEM Private Key: plik oci_api_key.pem
OCI Cloud Storage PEM Key Fingerprint: 36:76:14:2a:5b:65:02:d5:98:d4:b5:8b:df:d6:d0:e0
Konfiguracja wydajności powierzchni magazynowania
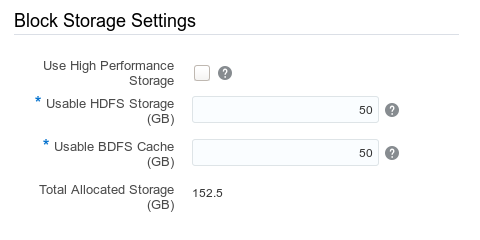
Use High Performance Storage: [ ]
- Zwiększa wydajność Hadoop Distributed File System (HDFS)
Usable HDFS Storage (GB): 50
- Przestrzeń dla przechowywania danych
- Przy domyślnej replikacji 2 razy większa
- 5% zarezerwowane na logi
- Maksymalna powierzchnia to 438 TB
Usable BDFS Cache (GB): 50
- Maksymalnie to 74 TB
Powiązania między usługami
Łączymy usługi tak, aby mogły się ze sobą komunikować
Podsumowanie
Po prawej stronie mamy możliwość pobrania pliku xml z wybraną konfiguracją.