Instalacja CDP za pomocą Cloudera Managera on premise
Instalacja CDP za pomocą Cloudera Managera on premise
Instrukcja instalacji Cloudera Data Platform (CDP) + Cloudera Manager (CM) na CentOS w środowisku nieprodukcyjnym w celu prezentacji lub jako proof-of-concept. Instalujemy Cloudera Manager z JDK, bazą PostgreSQL, usługą Manager Server, Manager Agent i Cloudera Runtime.
W artykule mamy opis platformy za pomocą dwóch skrótów, które określają platformę do zarządzania danymi.
| Skrót | Opis |
|---|---|
| CDP | Cloudera Data Platform |
| CDH | Cloudera Distribution Hadoop |
Termin CDH określa Cloudera’s Open Source Platform Distrbution including Apache Hadoop. Podczas instalacji niektóre nazwy pakietów w repozytoriach mają tajemnicze cdh7 w nazwie. Wynika to z pewnych powodów technicznych powiązanych z upgradeami. Generalnie mówimy o CDP i możemy przyjąć, że cdh7=cdp :)
Kolejny skrót to CM tj. orchestrator klastrów Big Data, posiada zautomatyzowane procedury pomocne przy pracy na co dzień dla administartorów.
Koncepcja
Naszym środowiskiem będzie 9 maszyn postawionych on premise. Pierwsza maszyna będzie pełniła funkcję zarządcy a pozostałe to składniki klastra. Kolejna porcja skrótów:
DNData Node - węzły przechowujące dane (bloki z danymi)NNName Node - węzeł zarządzający ww danymi
[Cloudera Manager]
|
[NameNode + pozostałe_serwisy]
|
----------------------------------------
| | | | | | |
[DataNode] | [DataNode] | [DataNode] | [DataNode]
| | |
[DataNode] [DataNode] [DataNode]
___________________________________________________
Schema Powered by Vim The power tool for everyone
Przygotowanie Systemu Operacyjnego
Ze strony projektu CentOS pobieramy obraz iso do instalacji. Link do wyboru architektury i typu https://www.centos.org/download/. Bezpośredni link: http://isoredirect.centos.org/centos/7/isos/x86_64/ również zaszyty w kodzie QR poniżej.
 |
Wspierana wersja CentOS
Tabelka przedstawia jaki system operacyjny jest kompatybilny z wersją Cloudery
| CentOS | Wersja CDP | |
|---|---|---|
| 7.9, 7.8, 7.7, 7.6, 7.5, 7.4, 7.3, 7.2 | 7.3.x | |
| ! | 7.9, 7.8, 7.7, 7.6, 7.5, 7.4, 7.3, 7.2 | 7.2.x |
| 7.6, 7.5, 7.4, 7.3, 7.2 | 7.1.x | |
| 7.6, 7.5, 7.4, 7.3, 7.2 | 7.0.x |
Wykrzyknik wskazuje z jakiej wersji CM/CDP będziemy korzystać.
Wspierane systemy plikow pod HDFS-a
- ext3
- ext4
- xfs
Wersja jvm
| CDP | Oracle JDK | OpenJDK | |
|---|---|---|---|
| 7.3.x | 1.8 | 1.8, 11.0.3+ | |
| ! | 7.2.x | 1.8 | 1.8, 11.0.3+ |
| 7.1.x | 1.8 | 1.8, 11.0.3+ | |
| 7.0.x | 1.8 | 1.8, 11.0.3+ |
Zalecaną wersją jest OpenJDK 1.8u212. Należy pamiętać, że wersje JDK 7 i niższe nie są wspierane dla CM 6.x i CDP 6.x.
Wykrzyknik wskazuje z jakiej wersji CM/CDP będziemy korzystać.
Kompatybilność wersji CDP i CM
Aplikacje mają konwencję nazewnictwa wersji: <major>.<minor>.<maintenance>. Wersja <major>.<minor> Cloudera Managera musi być identyczna lub wyższa z wersją CDP, wersja <minor> jest tu pomijana.
Przykłady:
| CM | ok? | CDP |
|---|---|---|
| 7.0.9 | [x] | 7.0.0 |
| 7.1.9 | [x] | 7.0.0 |
| 7.2.9 | [x] | 7.0.1 |
| 7.2.9 | [x] | 7.2.0 |
| 7.2.9 | [x] | 7.1.9 |
| 7.2.9 | [ ] | 7.3.9 |
Wymagania sprzętowe
Dla naszego środowiska (to jest lab = usługa nieprodukcyjna) założyliśmy, że każda maszyna musi mieć
- Dysk 40 GB
- 8 vCPU
- RAM 24 GB
- DN 8 x 2 GB
Generowanie i dystrybucja kluczy ssh
Po instalacji OS logujemy się na pierwszą maszynę i tworzymy parę kluczy do połączeń po ssh. Najszybciej wykonać to poleceniem ssh-keygen, właściwe polecenie:
/usr/bin/ssh-keygen -t rsa
Za pomocą skryptu ssh-copy-id zawartość pliku id_rsa.pub dopiszemy do pliku authorized_keys na pozostałych maszynach. Na pierwszym (pierwszy) hoście możemy tego dokonać wykonując polecenie
[root@hadoop160 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Nim prześlemy nasz klucz publiczny na inne hosty to sprawdzamy czy możemy nawiązać połączenie za pomocą ssh do samych siebie a więc logując się do tej samej maszyny na której jesteśmy.
[root@hadoop160 ~]# ssh 0
The authenticity of host '0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:LDxMU+4lcrblD9c/VsUznP4adzI5Rc+sp6wFiJNUn5A.
ECDSA key fingerprint is MD5:6f:a2:20:97:1c:2d:e4:31:cd:4e:4d:f9:a4:15:e1:90.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '0,0.0.0.0' (ECDSA) to the list of known hosts.
Last login: Tue Dec 21 16:59:22 2021 from 192.168.133.250
Jeśli mamy podobny wynik to używamy skryptu ssh-copy-id do wykonania tego samego zadania tylko na innych hostach.
Należy zwrócić uwagę, że domyślnie systemy modern linux mają wyłączoną możliwość zdalnego logowania się jako administrator (przeważnie jest to użytkownik
root). Rozwiązaniem może być logowanie się jako inny użytkownik a następnie podniesienie swoich uprawnień za pomocą poleceniasudolub dopisanie w/etc/ssh/sshd_configlinijkiPermitRootLogin yesi restart usługisystemctl restart sshd.
DHCP w sieci
Protokół IP wersji 6 nie jest wspierany i musi być wyłączony.
W naszym środowisku musimy zadbać o niezmienność adresu IP z nazwą domenową każdego z hostów, gdyż każdy nod (węzęł) w klastrze identyfikuje się nazwą domenową. Najprostszym rozwiązaniem będzie przypisanie na stałe adresów IPv4 dla sieci w której będzie działać Hadoop. W naszym przypadku należy utworzyć plik net-172.31.184-24.xml, treść poniżej.
<network connections='1'>
<name>net-172.31.184-24</name>
<uuid>00000000-0172-0031-0184-000000000000</uuid>
<forward mode='nat'>
<nat>
<port start='1024' end='65535'/>
</nat>
</forward>
<mac address='40:00:ac:1f:b8:fa'/>
<ip address='172.31.184.250' netmask='255.255.255.0'>
<dhcp>
<range start='172.31.184.240' end='172.31.184.249'/>
<host mac='40:00:ac:1f:b8:01' name='hadoop001' ip='172.31.184.1'/>
<host mac='40:00:ac:1f:b8:02' name='hadoop002' ip='172.31.184.2'/>
[...]
</dhcp>
</ip>
</network>
a następnie go zaimportować za pomocą polecenia
root@bigdatalab:~# virsh net-define net-172.31.184-24.xml
Network net-172.31.184-24 defined from net-172.31.184-24.xml
Tabelka przedstawia właściwą konfiguracje klastra w 2/3 warstwie sieci:
| Rola | MAC adres | nazwa hosta (fqdn) | adres IPv4 |
|---|---|---|---|
| Manager | 40:00:ac:1f:b8:9f | hadoop159.bigdatalinux.org | 172.31.184.159 |
| Worker | 40:00:ac:1f:b8:a0 | hadoop160.bigdatalinux.org | 172.31.184.160 |
| Worker | 40:00:ac:1f:b8:a1 | hadoop161.bigdatalinux.org | 172.31.184.161 |
| Worker | 40:00:ac:1f:b8:a2 | hadoop162.bigdatalinux.org | 172.31.184.162 |
| Worker | 40:00:ac:1f:b8:a3 | hadoop163.bigdatalinux.org | 172.31.184.163 |
| Worker | 40:00:ac:1f:b8:a4 | hadoop164.bigdatalinux.org | 172.31.184.164 |
| Worker | 40:00:ac:1f:b8:a5 | hadoop165.bigdatalinux.org | 172.31.184.165 |
| Worker | 40:00:ac:1f:b8:a6 | hadoop166.bigdatalinux.org | 172.31.184.166 |
| Worker | 40:00:ac:1f:b8:a7 | hadoop167.bigdatalinux.org | 172.31.184.167 |
Instalacja wymaganych składników OS i narzędzi
Aktualizacja OS i instalacja narzędzi
yum update -y
yum -y upgrade
yum install -y epel-release
yum install -y wget htop ntp byobu ncdu python-psycopg2
Host Name i wpisy w pliku hosts
172.31.184.159 hadoop159.bigdatalinux.org hadoop159
172.31.184.160 hadoop160.bigdatalinux.org hadoop160
172.31.184.161 hadoop161.bigdatalinux.org hadoop161
172.31.184.162 hadoop162.bigdatalinux.org hadoop162
172.31.184.163 hadoop163.bigdatalinux.org hadoop163
172.31.184.164 hadoop164.bigdatalinux.org hadoop164
172.31.184.165 hadoop165.bigdatalinux.org hadoop165
172.31.184.166 hadoop166.bigdatalinux.org hadoop166
172.31.184.167 hadoop167.bigdatalinux.org hadoop167
for i in "" --pretty --static --transient ; do
hostnamectl set-hostname hadoop159.bigdatalinux.org ${i} ; done
Synchronizacja czasu (ntp)
yum install -y ntp
systemctl start ntpd
systemctl enable ntpd
Sprawdzamy stan synchronizacji poleceniem ntpstat lub ntptime.
Coraz częściej zaleca się używanie
chrony. Więcej pod adresem https://chrony.tuxfamily.org/
Security-Enhanced Linux + Firewall
SELinux nie powinien blokować działać CDP i CM. Na potrzeby naszego laba będzie on wyłączony. Rzecz ma się podobnie dla iptables (usługi firewalld) żadne regułki filtrowania sieciowego nie będą włączone.
SELinux
Zauważmy, że plik /etc/sysconfig/selinux wskazuje (jest linkiem) na /etc/selinux/config, więc zmiany możemy dokonac w jednym miejscu.
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
Przed zmianą było SELINUX=enforcing a po zmianie SELINUX=disabled. Jeśli nie chcemy restartować systemu operacyjnego to możemy wykonać polecenie setenforce 0 a następnie sprawdzić poleceniem getenforce (oczekiwany wynik: Permissive). W przypadku rebootu getenforce zwróci Disabled.
Firewalld
W pierwszym poleceniu wyłączamy autostart usługi przy starcie systemu. W drugim poleceniu zatrzymujemy ją a w ostatnim sprawdzamy w poszukiwaniu oczekiwanego statusu Active: inactive (dead).
systemctl disable firewalld
systemctl stop firewalld
systemctl status firewalld
Pobieramy instalator CM
Będąc zalogowanym na maszynie zarządzającej (tu hadoop159.bigdatalinux.org) pobieramy a następnie uruchamiamy instalator Cloudera Managera
wget https://archive.cloudera.com/cm7/7.4.4/cloudera-manager-installer.bin
chmod a+x cloudera-manager-installer.bin
./cloudera-manager-installer.bin
W celu odinstalowania należy uruchomić skrypt
/opt/cloudera/installer/uninstall-cloudera-manager.sh.
Instalacja CM
Akceptujemy warunki licencji
Po kilkuminutowej instalacji usługi CM

zostaje wyświetlony komunikat. Informuje o danych do zalogowania się do CM. Login to admin i hasło również admin. W przeglądarce wskazujemy adres IP maszyny i port 7180.
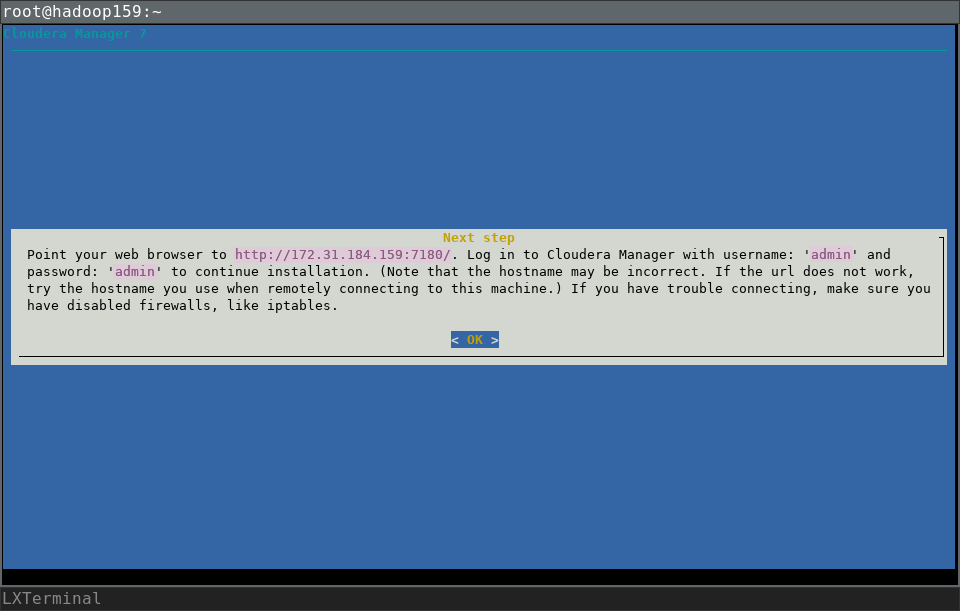
Tutaj http://172.31.184.159:7180
Pozostaje wybrać sposobu korzystania z Cloudera Manager. Do wyboru
- import licencji
Upload Cloudera Data Platform License - 60 dniowy trial
Try Cloudera Data Platform for 60 days
Wybieramy Try Cloudera Data Platform for 60 days a następnie akceptujemy postanowienia licencji zaznaczając Yes, I accept the Cloudera Standard License Terms and Conditions..
Tworzenie klastra
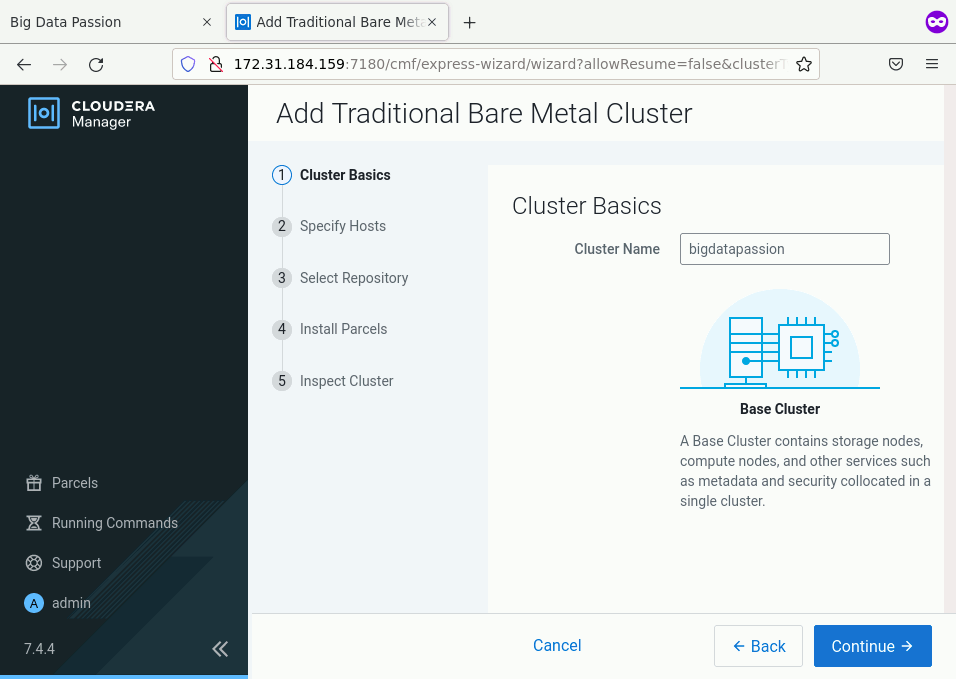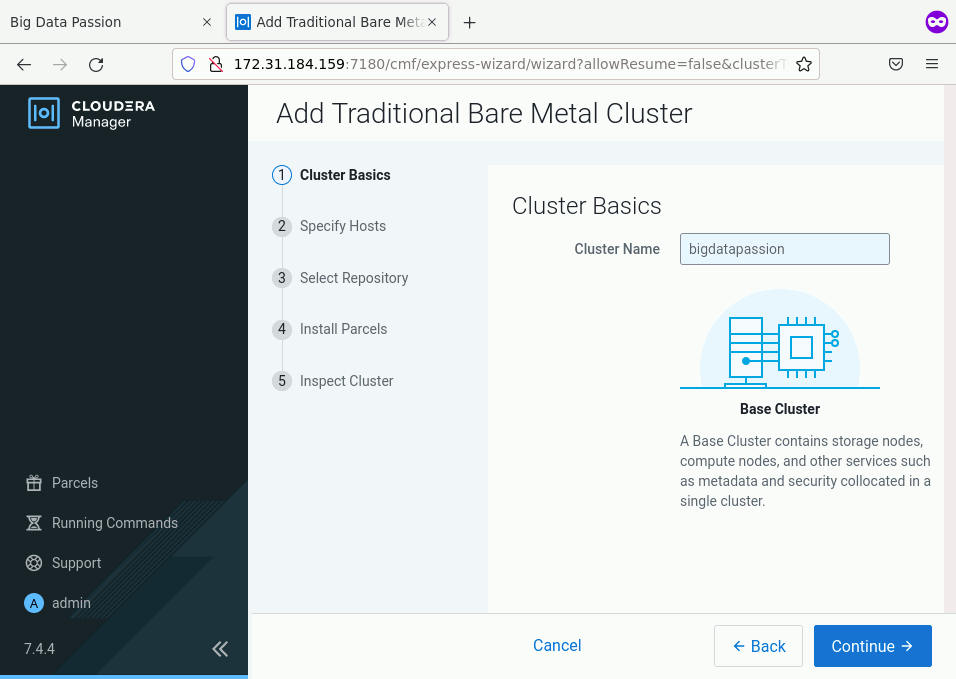
Krok 1
Domyślnie pojawi nam się wizard, który pomoże przy tworzeniu nowego klastra. Po wyświetleniu się tytułu Add Traditional Bare Metal Cluster przechodzimy dalej klawiszem Continue. Wpisujemy nazwę klastra bigdatapassion i ponownie wybieramy Continue.
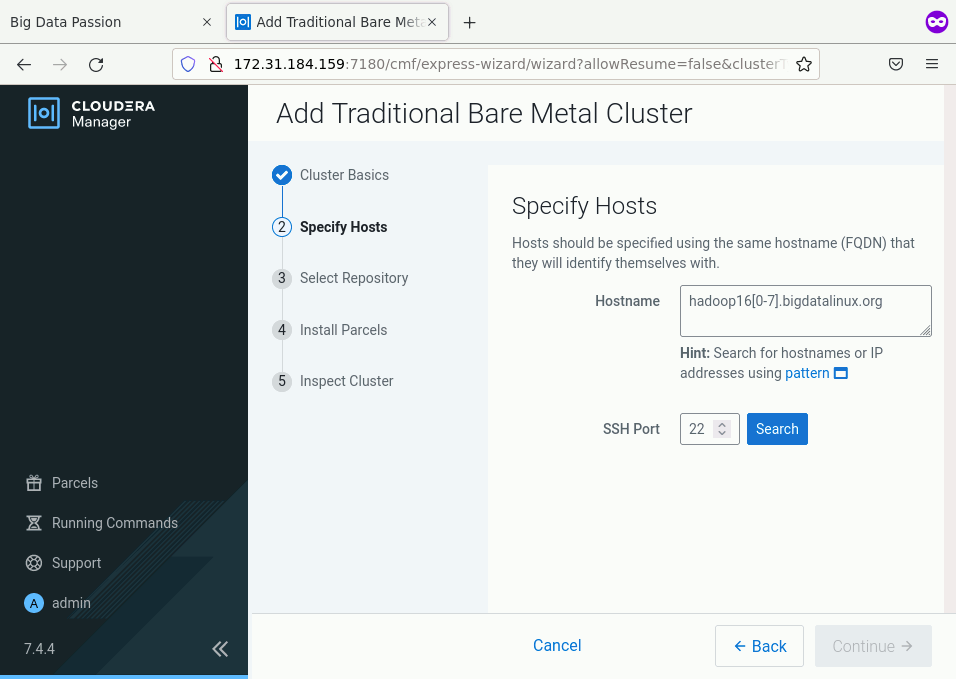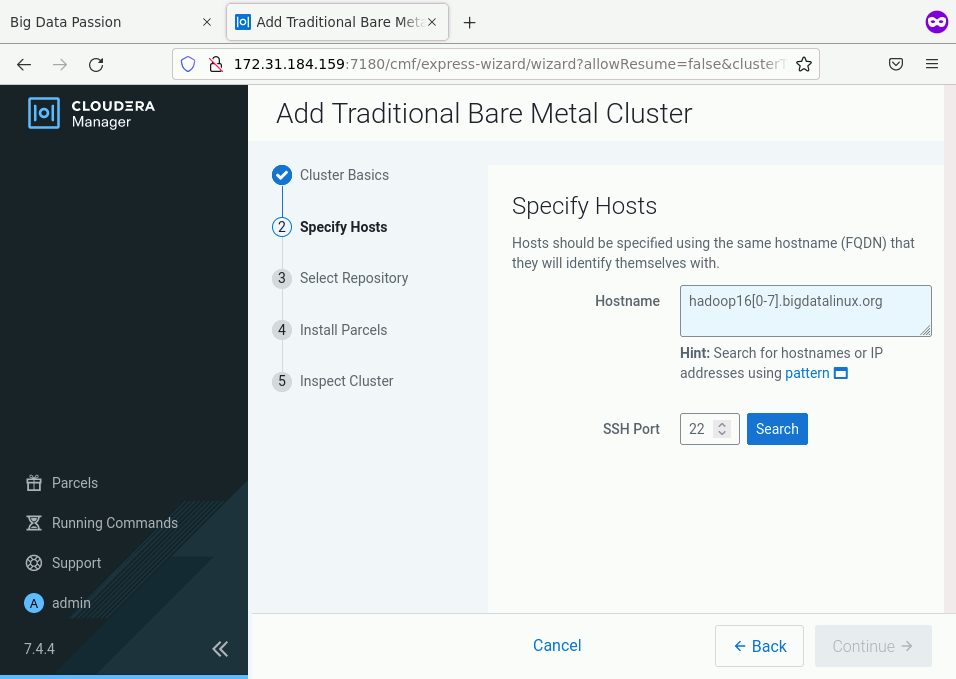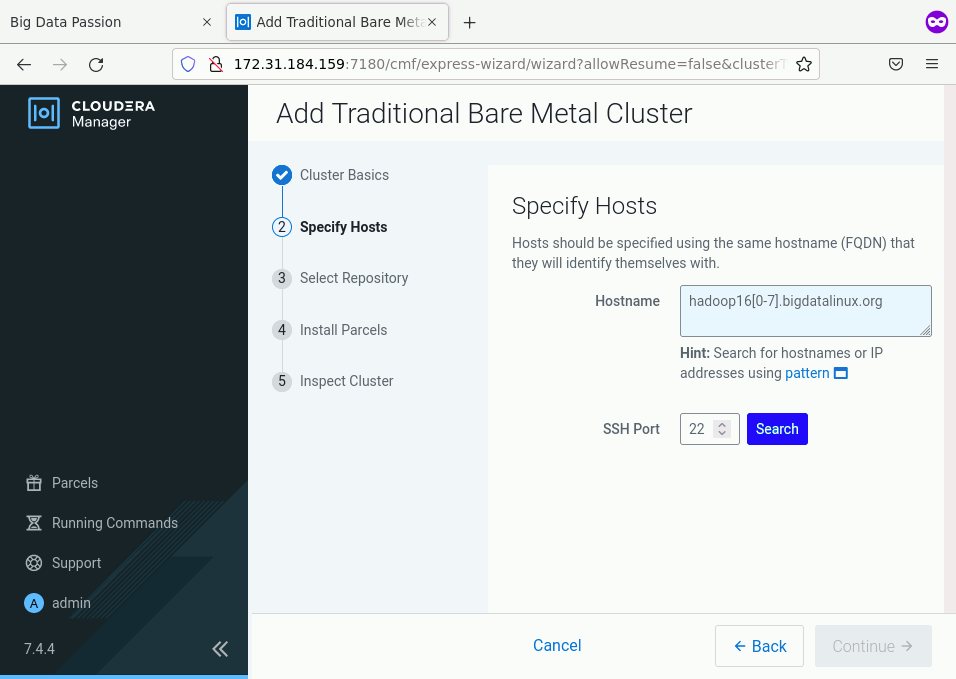
Krok 2
Wskazujemy hosty, które będą w klastrze CDP. Możemy tu w każdej linijce wkleić nazwę domenową każdego noda lub użyć wzorca hadoop16[0-7].bigdatalinux.org. Taka konstrukcja doda 8 nodów. Po wpisaniu nazwy hostów należy wybrać klawisz Search a po wyświetleniu się oczekiwanych maszyn i tu wybieramy Continue.
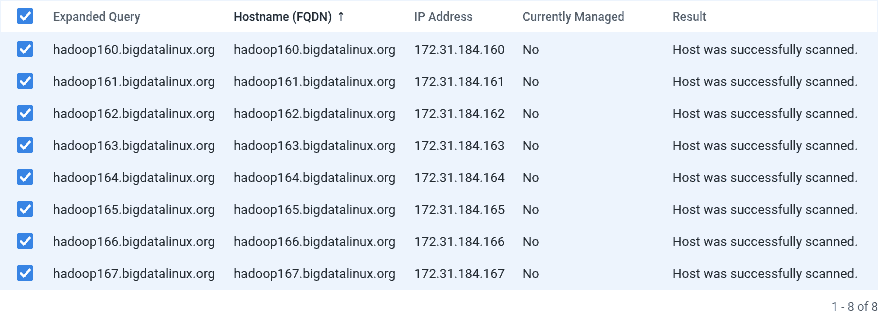
Krok 3
Na kolejnym ekranie wybieramy skąd będą pobierane repozytoria. Dla Repository Location używamy Cloudera Repository (Requires direct Internet access on all hosts.). Reszta pozostaje bez zmian.
Krok 4
Mamy 3 możliwości zainstalowania Java Development Kit (JDK).

-
- instalacja ręczna (np. za pomocą playbooka ansible) - Manually manage JDK
-
- instalacja zalecanej wersji przez CM - Install a Cloudera-provided version of OpenJDK
-
- instalacja z repo OS - Install a system-provided version of OpenJDK
Wybierzemy opcję numer 2 a więc Cloudera zainstaluje zalecaną wersję OpenJDK
Krok 5
Podczas instalacji Cloudery wymagany jest dostęp do konta root na każdym węźle. Zadbaliśmy o to podczas tworzenia klucza i jego dystrybucji na pozostałe hosty. SSH Username pozostaje bez zmian (tj. root). Musimy wskazać klucz prywatny i go uploadować. Z Authentication Method wybieramy 2. opcję All hosts accept same private key. Pojawi się możliwość wrzucenia pliku klucza prywatnego (nazwa: id_ed25519).
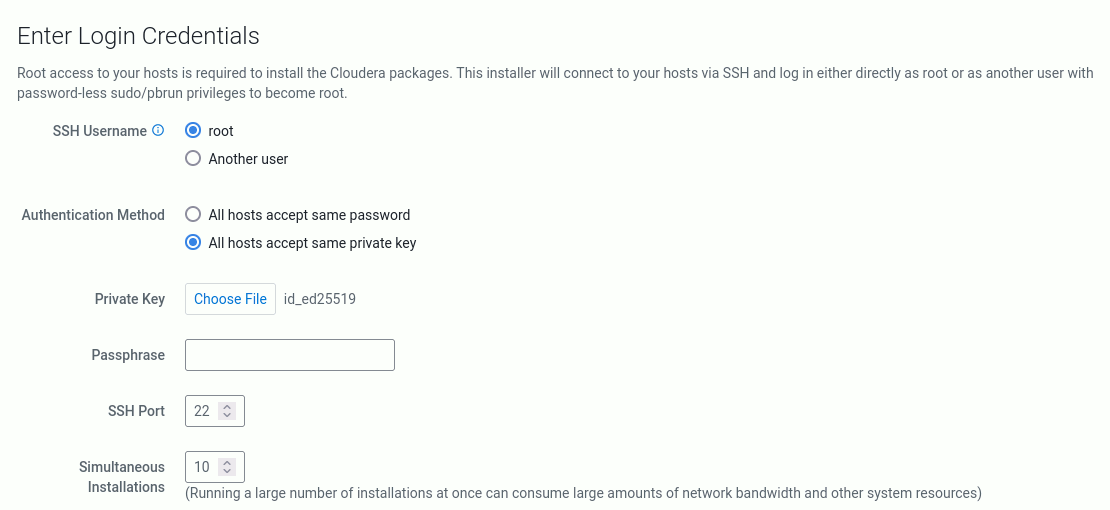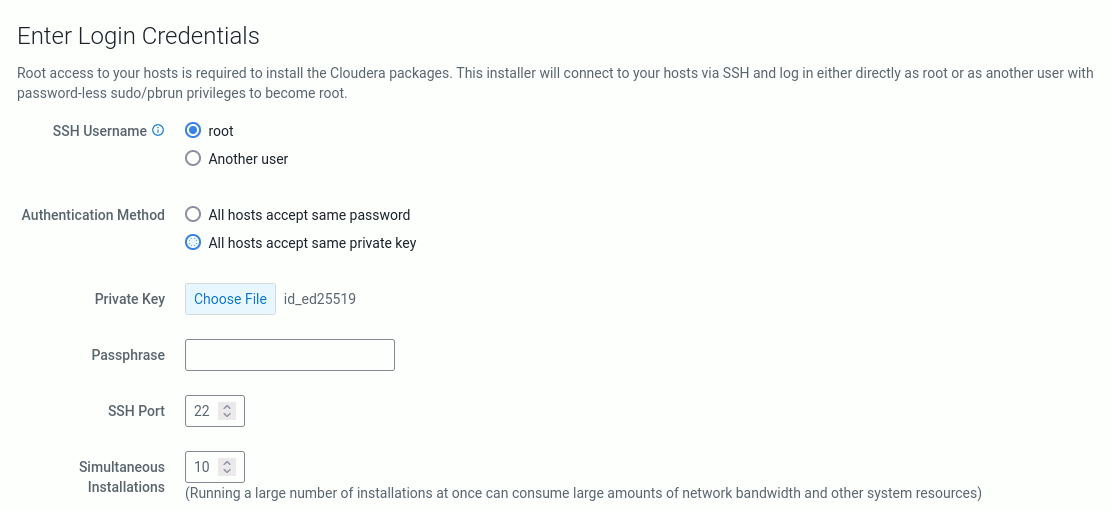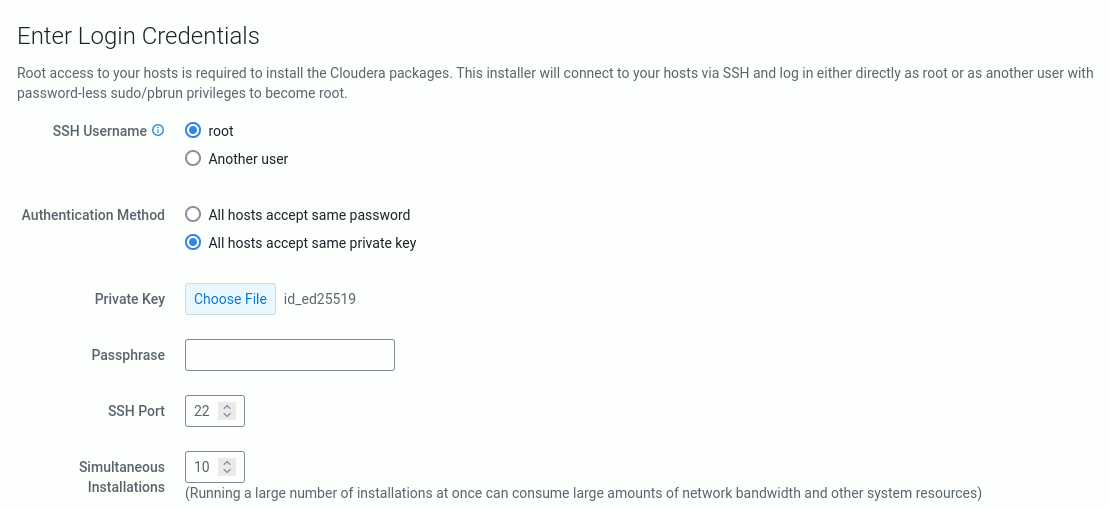
Krok 6
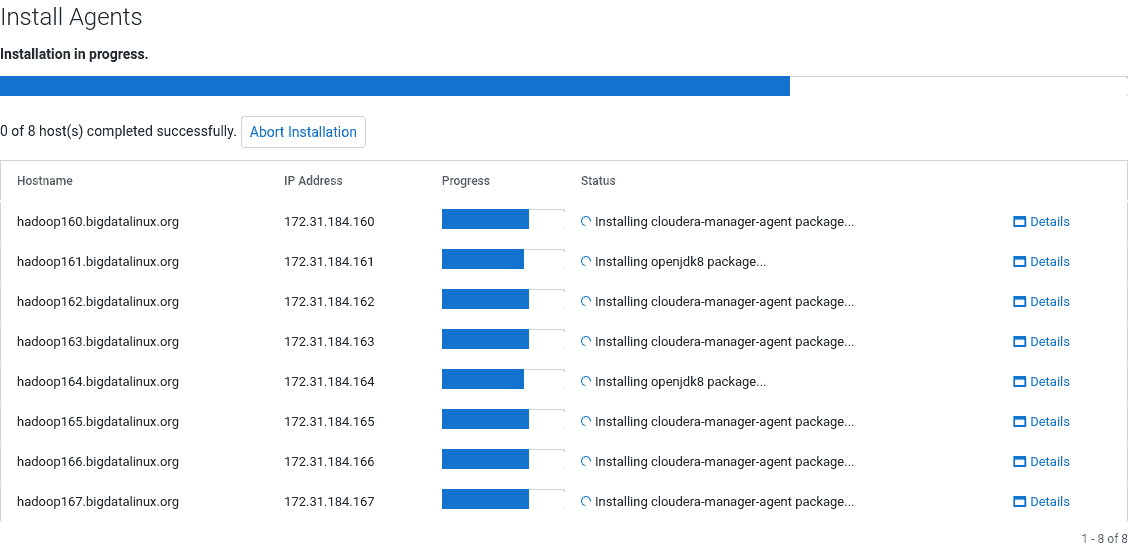
Po zakończeniu instalacji agentów na każdym węźle w statusie otrzymamy Installation completed successfully i podświetli się klawisz Continue i przechodzimy do kolejnego kroku.
Krok 7
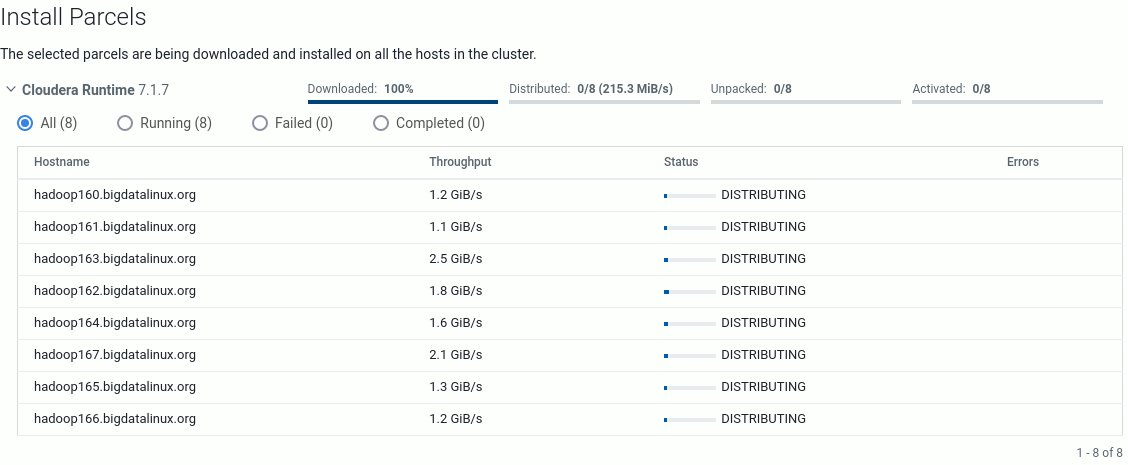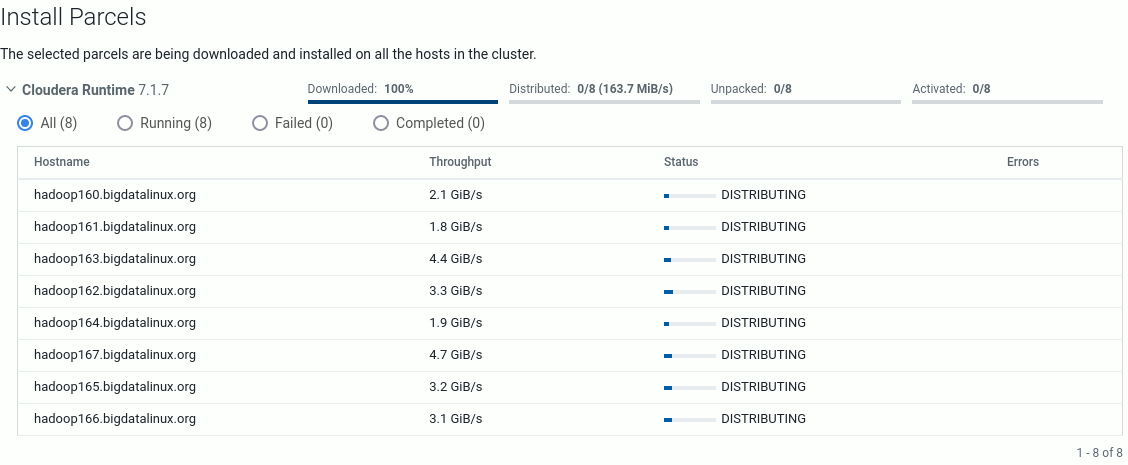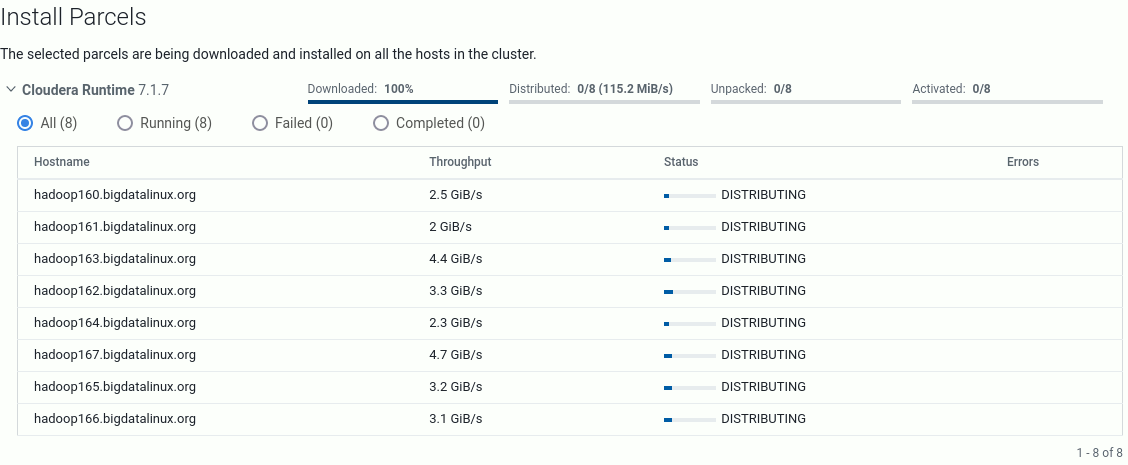
W nowej zakładce można podejrzeć już jakieś informacje o hostach http://172.31.184.159:7180/cmf/hardware/hosts.
Krok 8
W dwóch testach dokonujemy sprawdzenia jakości połączeń sieciowych i kondycji komponentów klastra.

Problem może wystąpić z nadmiernym używaniem swapu i włączonym Transparent Huge Page.

Pierwsze naprawiamy poleceniem (na każdym hoście)
echo "vm.swappiness=1" >> /etc/sysctl.conf
a kolejne
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Jeśli nie dokonamy rekomendowanych zmian należy wybrać I understand the risks of not running the inspections or the detected issues, let me continue with cluster setup.
Instalacja składników klastra
Z menu głównego po lewej stronie rozwijamy Cluster a w nim mamy 2 sposoby dodania usług do nowo utworzonego klastra.
- Wybieramy
Add Services, wtedy uruchomimy wizard a w nim mamy kilka predefiniowanych zestawów aplikacji. - Gdybyśmy wybrali nazwę utworzonego klastra tj.
bigdatapassionprzechodzimy do ekranu w którego górnej części jest rozwijane menuActionsgdzie i tu mamy możliwość wybrania składników klastra obliczeniowego pod przyciskiemAdd service.
Po wybraniu Add Services mamy 7 kroków
Krok 1 - wybór usług

Do wyboru 3 gotowe konfiguracje lub własna kompozycja usług
- Data Engineering
- Data Mart
- Operational Database
- Custom Services (*)
Wybierając ostatnią możliwość zainstalujemy tylko hadoopowy system plików (HDFS) i wybierzemy Continue.
Krok 2 - przypisanie hostów do roli
Ponieważ wszystkie 8 hostów ma taką samą konfigurację sprzętową (ilość podpiętych zasobów dyskowych) to wybieramy, że wszystkie nody będą DN a więc węzłami, które będą odpowiedzialne za przechowywanie danych na HDFS-ie. Pierwszy host będzie pełnił rolę NN a więc usługi zarządzającej rozmieszczeniem danych na DN.

Wybieramy okienko pod DataNode x 7 New i z menu rozwijanego All Hosts (alternatywnie: Custom... i tu checkboksami zaznaczamy wszystkie wiersze). Parametry pozostałem dla roli HDFS jak i Cloudera Management Service pozostają bez zmian.
Krok 3 - podłączenie do bazy danych

Wskazujemy z jakiej bazy danych usługa Reports Manager ma korzystać. Wybór jest pomiędzy:
- uruchomioną już bazę danych (zainstalowaną na zarządcy a więc na maszynie
hadoop159.bigdatalinux.org- tam gdzie działaCloudera Manager - własną zainstalowaną ręcznie / uruchomioną na innym hoście.
Do wyboru mamy 3 rodzaje
- MySQL
- PostgreSQL
- Oracle
Dane autoryzacji do DB na maszynie zarządzającej są wyświetlane w interfejsie webowym, można je również odczytać z pliku /etc/cloudera-scm-server/db.mgmt.properties
grep "REPORTSMANAGER" /etc/cloudera-scm-server/db.mgmt.properties
com.cloudera.cmf.REPORTSMANAGER.db.type=postgresql
com.cloudera.cmf.REPORTSMANAGER.db.host=hadoop159.bigdatalinux.org:7432
com.cloudera.cmf.REPORTSMANAGER.db.name=rman
com.cloudera.cmf.REPORTSMANAGER.db.user=rman
com.cloudera.cmf.REPORTSMANAGER.db.password=tXHf3CYkcp
Zastosujemy domyślne rozwiązanie i wykorzystamy już istniejącą bazę. Koniecznym krokiem jest Test Connection a wtedy podświetli się Continue.
Krok 4 - dodatkowe ustawienia
Dla naszego wyboru nie ma tu żadnej dodatkowej konfiguracji.
Krok 5 - podgląd planowanych zmian
Na tym ekranie dokonujemy zmiany usuwając dysk systemowy jako miejsce przechowywania danych na HDFSie. W DN Data Directory usuwamy pierwszy wpis /dfs/dn.
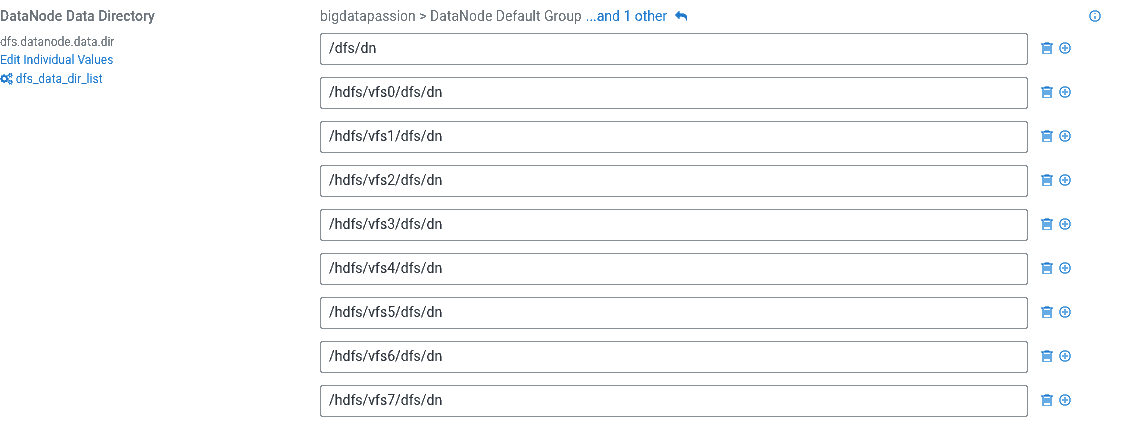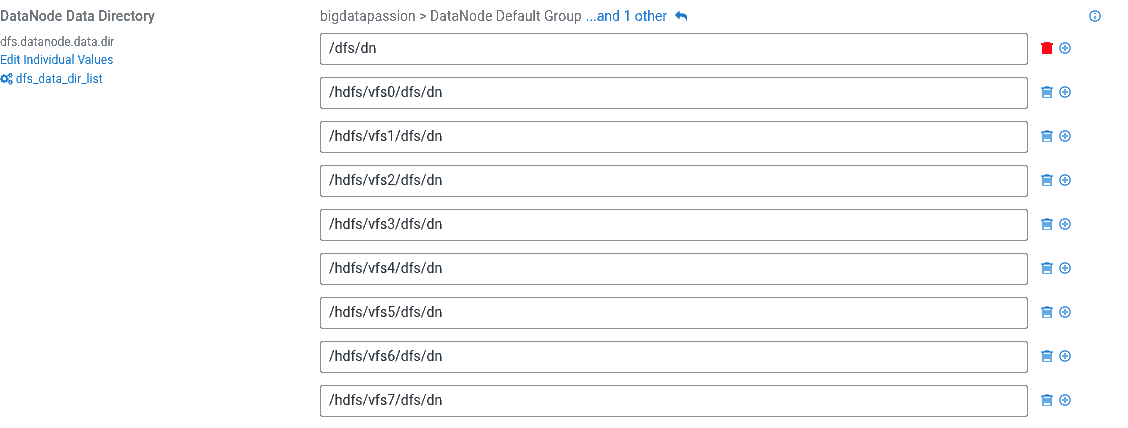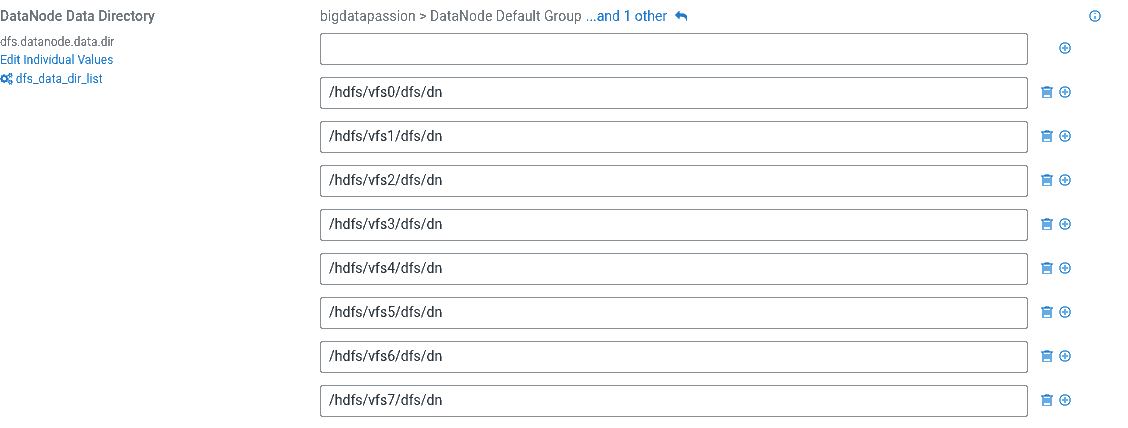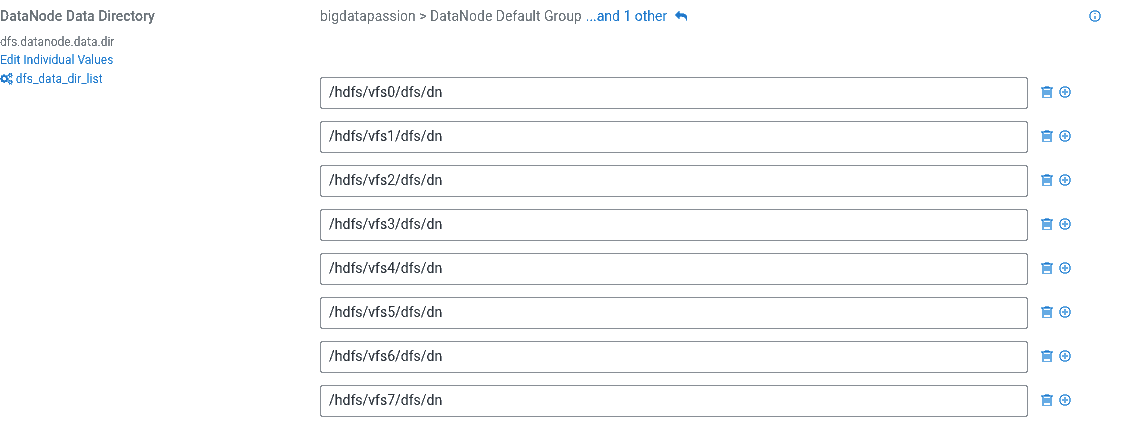
Krok 6 - uruchomienie usług
Proces powinien potrwać ok. minuty a stanem oczekiwanym jest Status: Finished.
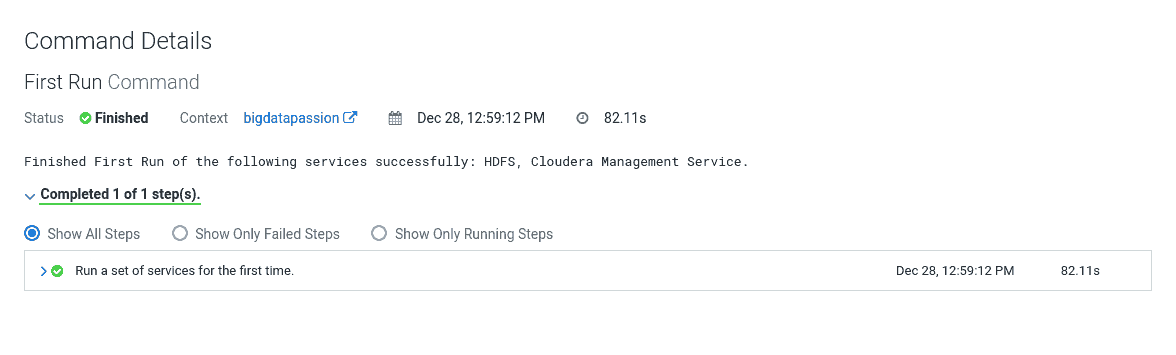
Krok 7 - podsumowanie

Podsumowanie
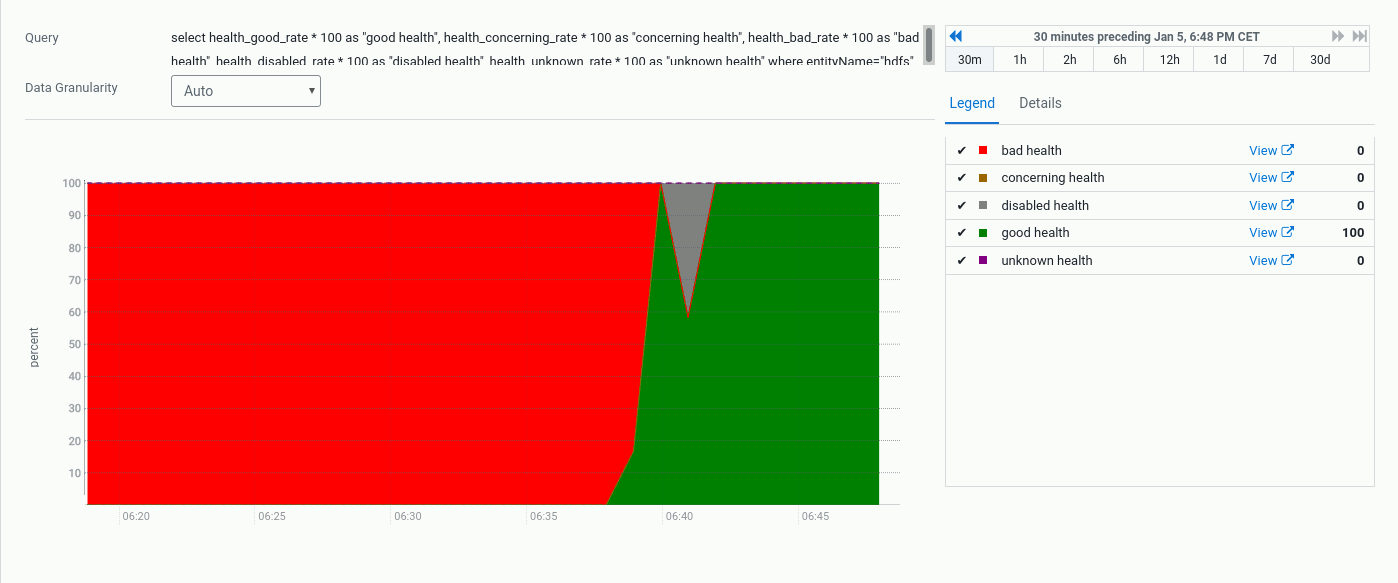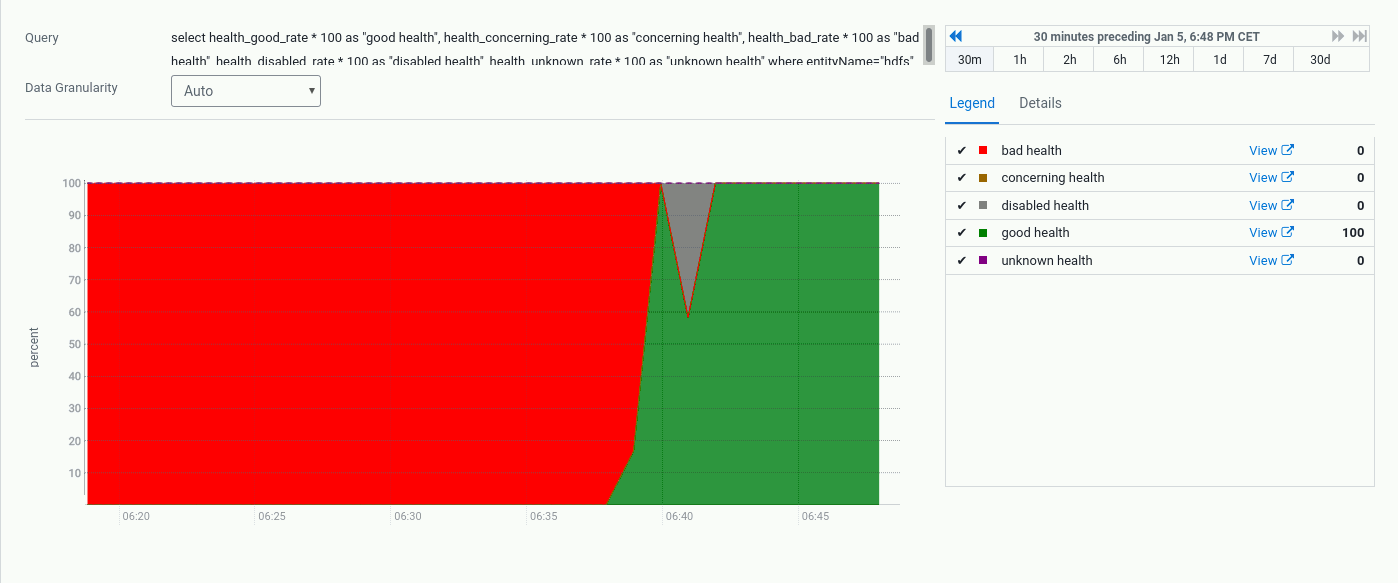
Otrzymujemy ekran z wykresami.
Uwagi
Monitorowanie - zmiana progów ostrzeżeń
Konfiguracja z dyskami dla przechowywania danych dla DN wielkości 2 GB to tylko PoC, właściwa wielkość powinna być wyrażona w jednostkach TB. Domyślnie CM wyświetla ostrzeżenie/błąd, gdy jest mniej niż 5/10 GB wolnego miejsca na potrzeby HDFSa.
Rozwiązanie tej niedogodności to zmiana wartości progowych monitu o małej ilości wolnej przestrzeni każdego DN.
Rozwiązanie 1 - API
Za pomocą API dokonujemy zmian dla dwóch grup (tworzą się domyślnie)
hdfs-DATANODE-BASEhdfs-DATANODE-1
PUT /api/v31/clusters/bigdatapassion/services/hdfs/roleConfigGroups/hdfs-DATANODE-BASE/config
{
"items": [
{
"name": "datanode_data_directories_free_space_absolute_thresholds",
"value": "{\"warning\":1073741824,\"critical\":536870912}"
}
]
}
PUT /api/v31/clusters/bigdatapassion/services/hdfs/roleConfigGroups/hdfs-DATANODE-1/config
{
"items": [
{
"name": "datanode_data_directories_free_space_absolute_thresholds",
"value": "{\"warning\":1073741824,\"critical\":536870912}"
}
]
}
Rozwiązanie 2 - WebUI
Z menu po lewej stronie wybieramy Clusters a następnie nazwę naszego klastra, tu bigdatalinux. Z menu Configuration przechodzimy do Configurationt Search. W polu wyszukiwania wyszukujemy datanode directory free space - interesuje nas DataNode Data Directory Free Space Monitoring Absolute Thresholds. W przeciwieństwie do poprzedniego rozwiązaniu tu można wykonać zmianę za pomocą zmiany parametrów jednocześnie dla dwóch grup. Wystarczy zapisać zmianę (z ewentualnym komentarzem) za pomocą Ctrl+S i poczekać kilka minut za aktualizacją statusu.

Oczekiwany stan
Po wybraniu z menu Clusters po lewej stronie roli HDFS w pierwszej zakladce Status ujrzymy wykres Health wskazujący kiedy nastąpiła zmiana statusu.