Instalacja dystrybucji Hortonworks Data Platform 3.1 za pomocą Apache Ambari
Instalacja HDP 3.1 za pomocą Ambari 2.7 na systemie Red Hat / CentOS 7
Instrukcja instalacji dystrybucji Hortonworks Data Platform HDP 3.1 na maszynach z systemem Red Hat 7 lub CentOS 7.
Do instalacji zostanie użyte:
- HDP-3.1.0.0
- Apache Ambari w wersji 2.7.3.0
- CentOS 7 lub Red Hat 7
Instalacja może być przeprowadzona tylko na jednej maszynie oraz w klastrze. W przypadku jednej maszyny należy w każdym miejscu konfiguracji wskazać jeden i ten sam host. Wszystko usługi, zarówno typu master jak i slave, będą zainstalowane na tym jednym komputerze.
W przypadku systemów produkcyjnych jedyną zalecaną opcją jest instalacja w klastrze kilku maszyn. Jedną maszynę możemy wykorzystywać do celów testowych i developerskich.
Przygotowanie maszyn
Taką instalację możemy przeprowadzić w dowolnym środowisku, np. z użyciem VirtualBoxa lub chmury AWS
Klaster ssh
Jeśli chcemy wykonywać wybrane polecenia jednocześnie na wszystkich maszynach możemy użyć polecenia cssh.
cssh root@hdp1 root@hdp2 root@hdp3
Jeśli wolimy klasyczne ssh, logujemy się na każdą maszynę oddzielnie:
ssh root@hdp1
UWAGA: Wszystkie dalsze polecenia wykonujemy zalogowani jako użytkownik root
Dostęp do internetu
Żeby instalować dodatkowe pakiety musimy mieć dostęp do internetu. Jeśli nie jest on dostępny, można spróbować włączyć DHCP.
Aby włączyć ręcznie DHCP należy wykonać:
dhclient -v
W celu skonfigurowania tego na stałe warto zmienić wartość (ONBOOT=yes) w pliku /etc/sysconfig/network-scripts/ifcfg-eth0
yum install -y vim
vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
Włączamy logowanie root’a po haśle
Jeśli chcemy umożliwić logowanie użytkownika root po haśle ustawiamy parametr (PermitRootLogin yes) w pliku /etc/ssh/sshd_config
vim /etc/ssh/sshd_config
(UWAGA nigdy tego nie róbmy na produkcyjnych serwerach, NIGDY!)
Logowanie po SSH
Jeśli korzystamy z systemów Linux/Mac wygodnym rozwiązaniem może okazać się konfiguracja dostępu z swojego komputer i swojej konsoli. Żeby nie musieć podawać przy logowaniu ciągle hasła, warto wrzucić na maszynę wirtualną swój klucz publiczny by logować się bez hasła.
ssh-copy-id root@localhost -p 2222
ssh root@localhost -p 2222
Możliwość logowania do wszystkich maszyn możemy sprawdzić za pomocą polecenia:
for i in {1..5..1}; do ssh hdp${i} uptime; done
Aktualizacja systemu
Żeby pracować na najnowszej wersji systemu należy go zaktualizować
yum -y update
yum -y upgrade
Instalacja epel release
CentOS:
yum install -y epel-release
Red Hat:
cd /tmp
yum install -y wget
wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum install -y epel-release-latest-7.noarch.rpm
yum repolist
Instalacja kolejnych przydatnych narzędzi
yum -y install wget vim htop ntp openssh-server openssh-clients nano bash-completion tree mc byobu ncdu
Zmieniamy hostname (opcjonalnie)
Uwaga, ustawiamy nowe wpisy hostname tylko i wyłącznie wtedy gdy chcemy je zmienić na własne. W wielu przypadkach możemy zostawić obecne hosty o ile są jakieś dostępne.
Na każdej z maszyn ustawiamy inny hostname, na przykład:
hostnamectl set-hostname hdpx.bigdatapassion.com
hostnamectl set-hostname "Hortonworks Data Platform Node" --pretty
hostnamectl set-hostname hdpx.bigdatapassion.com --static
hostnamectl set-hostname hdpx.bigdatapassion.com --transient
gdzie x to numer danego węzła, czyli hdp1, hdp2 i tak dalej.
Jeśli mamy jedną maszynę możemy ustawić:
hostnamectl set-hostname sandbox.bigdatapassion.com
Status możemy sprawdzić
hostnamectl status
hostname
hostname -f
Polecenie hostname i hostname -f powinny zwracać tą samą wartość.
Konfiguracja hostów
Poniższe ustawienie jest nam niezbędne jeśli ustawiliśmy własne wpisy hostname (punkt wyżej) oraz nie mamy żadnego systemu DNS który mógłby informować nasze maszyny jaki hostname odpowiada jakiemu adresowi ip.
Żeby maszyny się “widziały” musimy każdej ustawić odpowiedni hostname:
192.168.172.201 hdp1.bigdatapassion.com
192.168.172.202 hdp2.bigdatapassion.com
192.168.172.203 hdp3.bigdatapassion.com
Dla maszyn które mają zarówno adresy prywatne jak i publiczne (np. AWS lub Oracle Cloud) powinniśmy ustawić te prywatne. Oczywiście lista zależy od liczby maszyn (w tym przypadku 3) oraz adresach ip które można sprawdzić za pomocą polecenia “ip a”.
Dla jednego serwera możemy użyć localhost/127.0.0.1:
127.0.0.1 sandbox sandbox.bigdatapassion.com
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
Konfigurujemy logowanie SSH bez hasła
Hadoop do działania wymaga by użytkownik systemowy mógł logować się do innych maszyn bez hasła za pomocą infrastruktury klucza prywatnego i publicznego, dlatego wykonujemy poniższe polecenia.
Na każdej maszynie generujemy zestaw kluczy:
ssh-keygen -f .ssh/id_rsa -t rsa -N ''
Na maszynie hdp1 wyświetlamy sobie klucz publiczny:
cat .ssh/id_rsa.pub
Pobrany klucz maszyny hdp1 wklejamy na każdej maszynie (także hdp1) do pliku:
vim .ssh/authorized_keys
Jeśli wszystko poszło jak trzeba z maszyny hdp1 możemy teraz zalogować się po SSH do każdej innej maszyny:
ssh hdp3.bigdatapassion.com
Jeśli instalujemy to na jednej maszynie wystarczy wykonać:
ssh-keygen -f .ssh/id_rsa -t rsa -N ''
ssh-copy-id sandbox.bigdatapassion.com
ssh sandbox.bigdatapassion.com
Wyłączamy selinux
Edytujemy plik /etc/sysconfig/selinux ustawiając SELINUX na disabled.
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
sestatus
Wyłączamy Firewall’a
systemctl disable firewalld
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld.service
systemctl stop firewalld.service
systemctl status firewalld.service
Włączamy serwer czasu NTP
yum install -y ntp
systemctl disable chrony.service
systemctl enable ntpd
systemctl start ntpd
systemctl status ntpd
systemctl enable ntpd.service
systemctl is-enabled ntpd.service
systemctl start ntpd.service
systemctl status ntpd.service
Umask
umask 022
echo umask 022 >> ~/.bash_profile
echo umask 022 >> /etc/profile
Restart maszyn
Teraz warto wykonać restart wszystkich maszyn poleceniem reboot
Instalacja Apache Ambari
UWAGA: Od teraz wszystkie operacje wykonujemy tylko na maszynie hdp1
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.3.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
yum repolist
yum update
Instalujemy Ambari
yum install ambari-server -y
Konfigurujemy Ambari
(W każdym pytaniu wybieramy odpowiedź domyślną klikając klawisz Enter za każdrym razem)
ambari-server setup
W przypadku ambari-server setup upewniamy się, że nie ma żadnych ostrzeżeń, zaś na wszystkie pytania odpowiadamy wartościami domyślnymi klikając enter:
[root@hdp1 ~]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)? y
Customize user account for ambari-server daemon [y/n] (n)?
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 1
To download the Oracle JDK and the Java Cryptography Extension (JCE) Policy Files you must accept the license terms found at http://www.oracle.com/technetwork/java/javase/terms/license/index.html and not accepting will cancel the Ambari Server setup and you must install the JDK and JCE files manually.
Do you accept the Oracle Binary Code License Agreement [y/n] (y)? y
Downloading JDK from http://public-repo-1.hortonworks.com/ARTIFACTS/jdk-8u112-linux-x64.tar.gz to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz
jdk-8u112-linux-x64.tar.gz... 100% (174.7 MB of 174.7 MB)
Successfully downloaded JDK distribution to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz
Installing JDK to /usr/jdk64/
Successfully installed JDK to /usr/jdk64/
Downloading JCE Policy archive from http://public-repo-1.hortonworks.com/ARTIFACTS/jce_policy-8.zip to /var/lib/ambari-server/resources/jce_policy-8.zip
Successfully downloaded JCE Policy archive to /var/lib/ambari-server/resources/jce_policy-8.zip
Installing JCE policy...
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? n
Configuring database...
Default properties detected. Using built-in database.
Configuring ambari database...
Checking PostgreSQL...
Running initdb: This may take up to a minute.
Initializing database ... OK
About to start PostgreSQL
Configuring local database...
Configuring PostgreSQL...
Restarting PostgreSQL
Creating schema and user...
done.
Creating tables...
done.
Extracting system views...
ambari-admin-2.7.3.0.139.jar
....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
Uruchamiamy Ambari
ambari-server start
Instalacja sterownika JDBC
Jeśli w naszym klastrze chcielibyśmy użyć narzędzia Apache Hive lub innego który używa biblioteki jdbc, konieczne będzie ściągnięcie i zarejestrowanie odpowiedniego sterownika jdbc za pomocą poniższego polecenia:
wget http://central.maven.org/maven2/mysql/mysql-connector-java/8.0.12/mysql-connector-java-8.0.12.jar
mv mysql-connector-java-8.0.12.jar /opt/
ll /opt/ | grep mysql
ambari-server setup --jdbc-db=mysql --jdbc-driver=/opt/mysql-connector-java-8.0.12.jar
Powyższy przykład dotyczy bazy MySQL, dla innej oczywiście potrzebny jest analogiczny sterownik.
Konfiguracja klastra HDP za pomocą Ambari UI
Następnie wchodzimy na adres: http://hdp1:8080 (lub inny wybrany hostname) i całą instalację kontynuujemy w trybie graficznym. Logujemy się jako admin / admin.
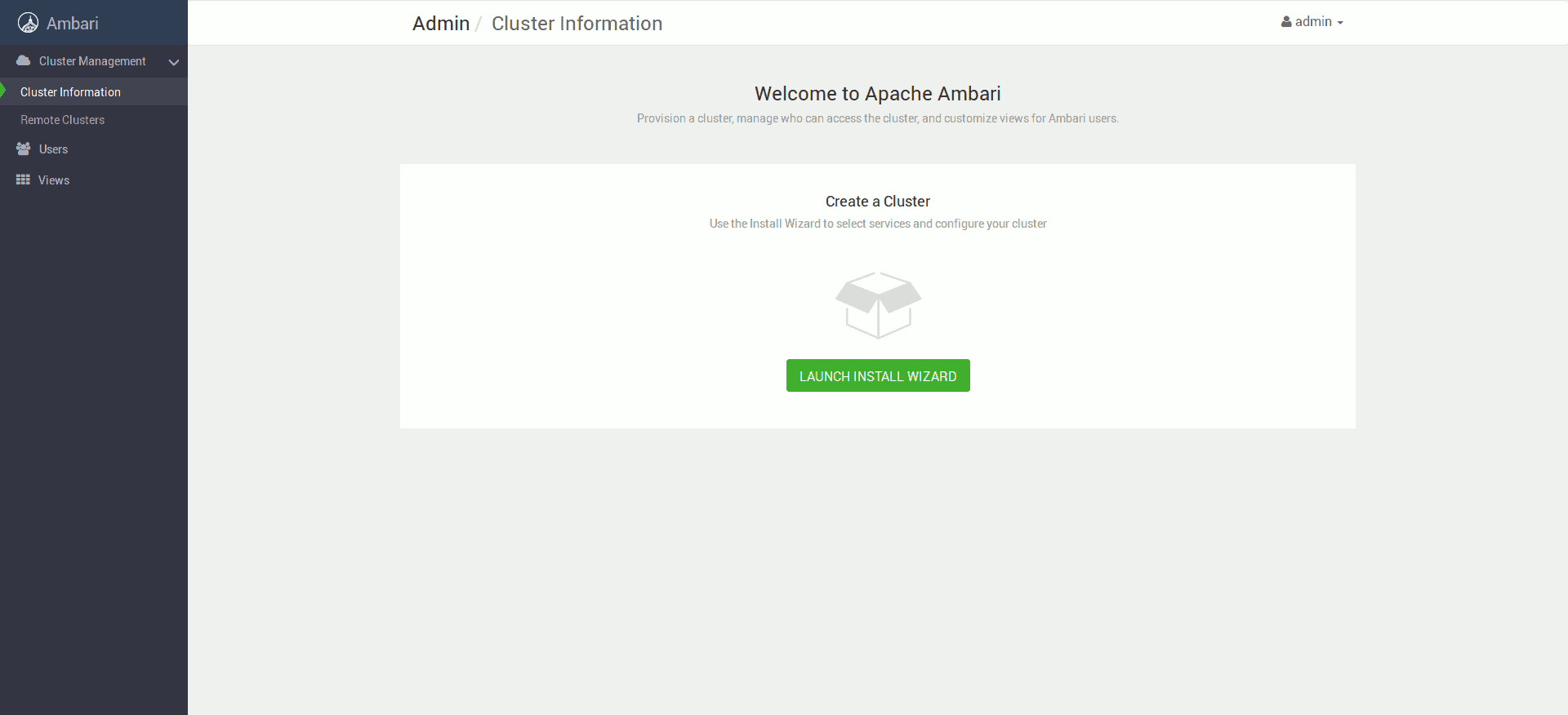
Następnie klikamy przycisk Launch Install Wizard
Ustawiamy nazwę naszego klastra

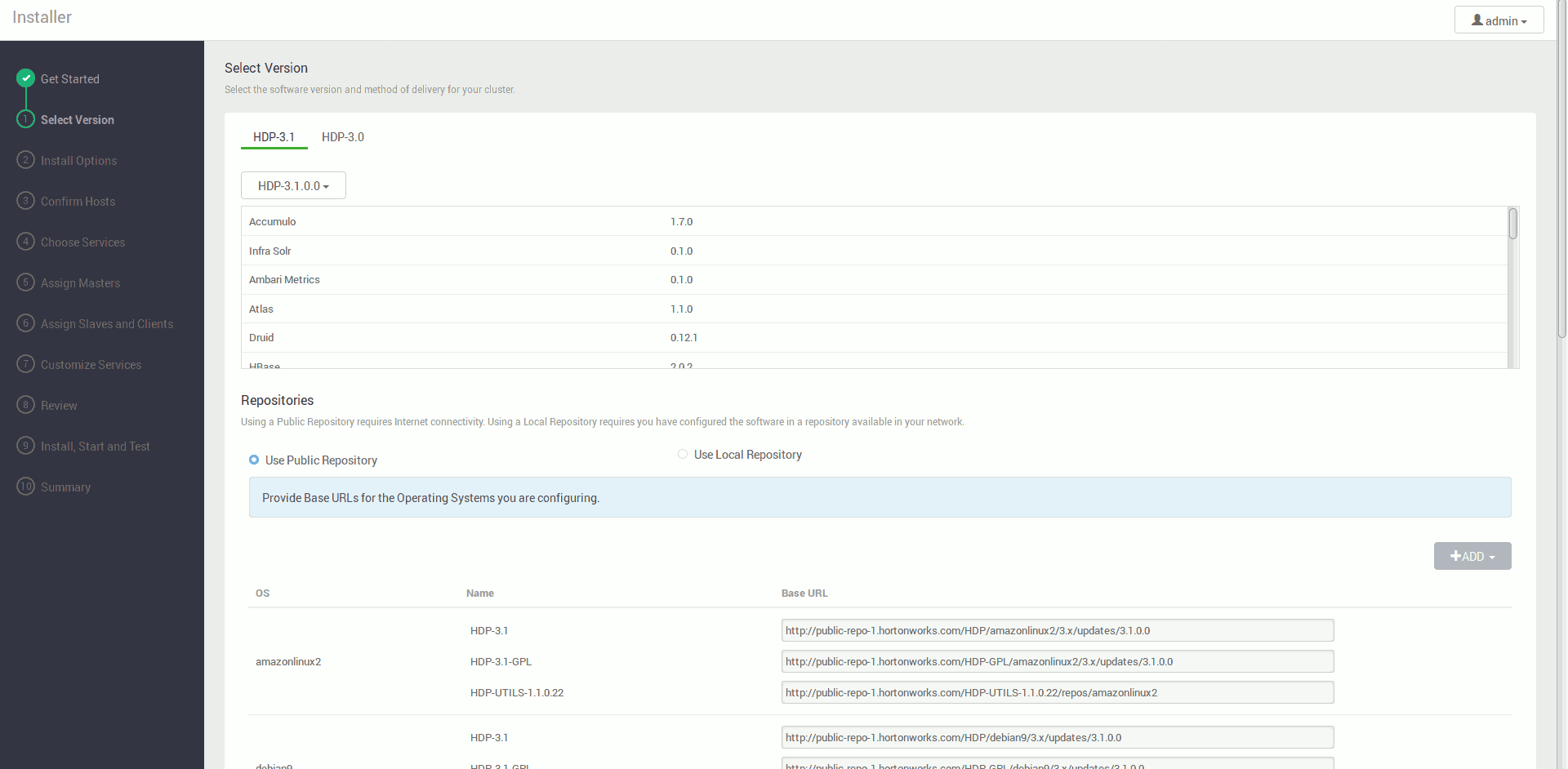
Wybieramy wersję dystrybucji którą chcemy zainstalować
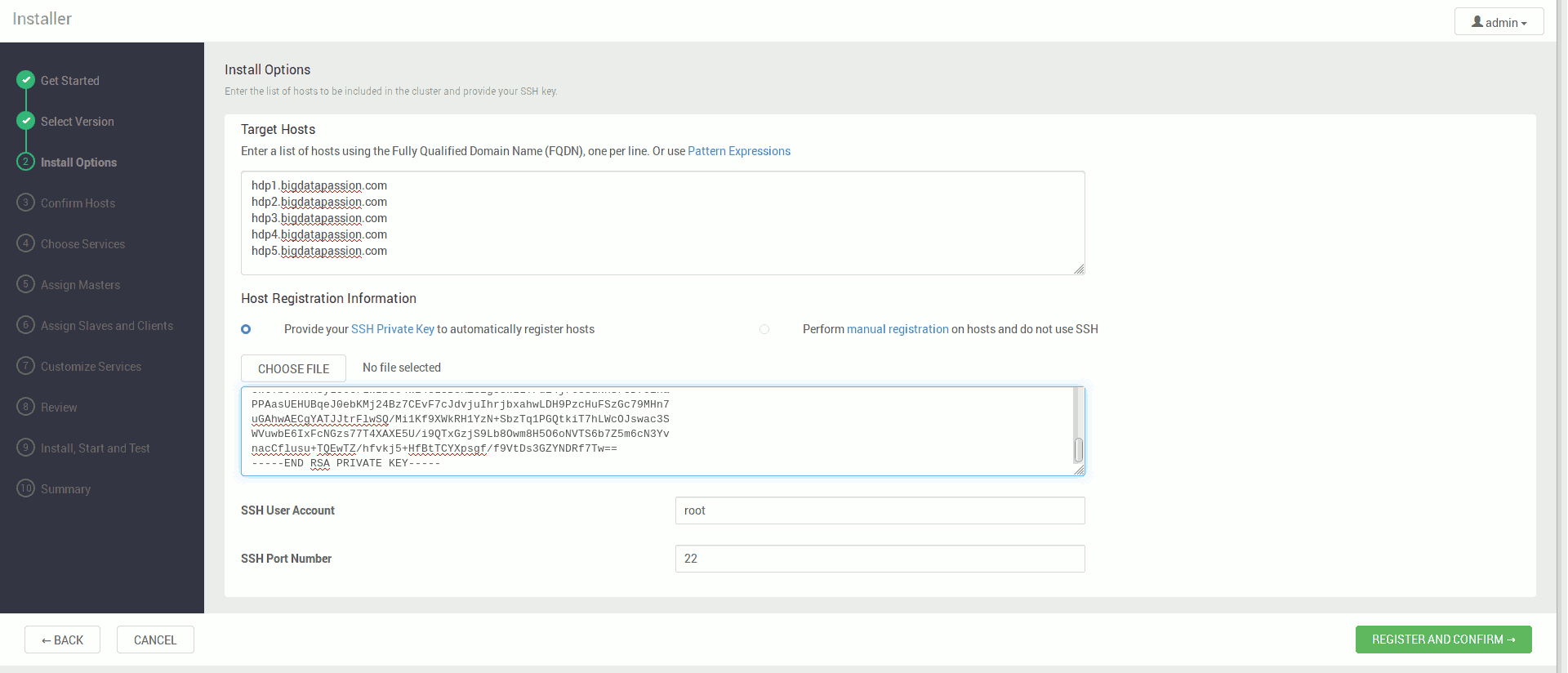
W kolejnym ekranie w polu Target Hosts wskazujemy pełne adresy wybranych maszyn na których chcemy postawić dystrybucję
hdp1.bigdatapassion.com
hdp2.bigdatapassion.com
hdp3.bigdatapassion.com
lub dla jednej maszyny:
sandbox.bigdatapassion.com
oraz wklejamy zawartość pliku /root/.ssh/id_rsa maszyny na której zainstalowaliśmy Ambari
Po kliknięciu Register and Confirm Ambari przygotowuje nasze maszyny do instalacji
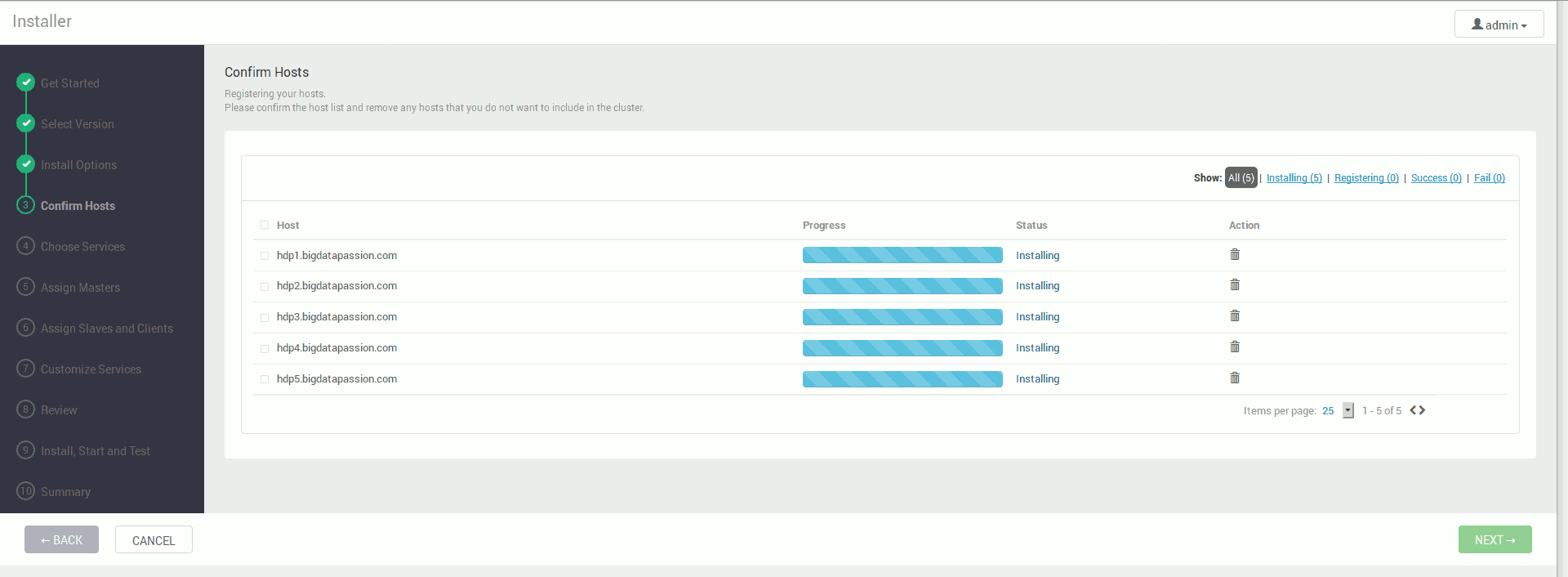
Po zakończonym procesie powinniśmy dostać informację o udanym przygotowaniu maszyn
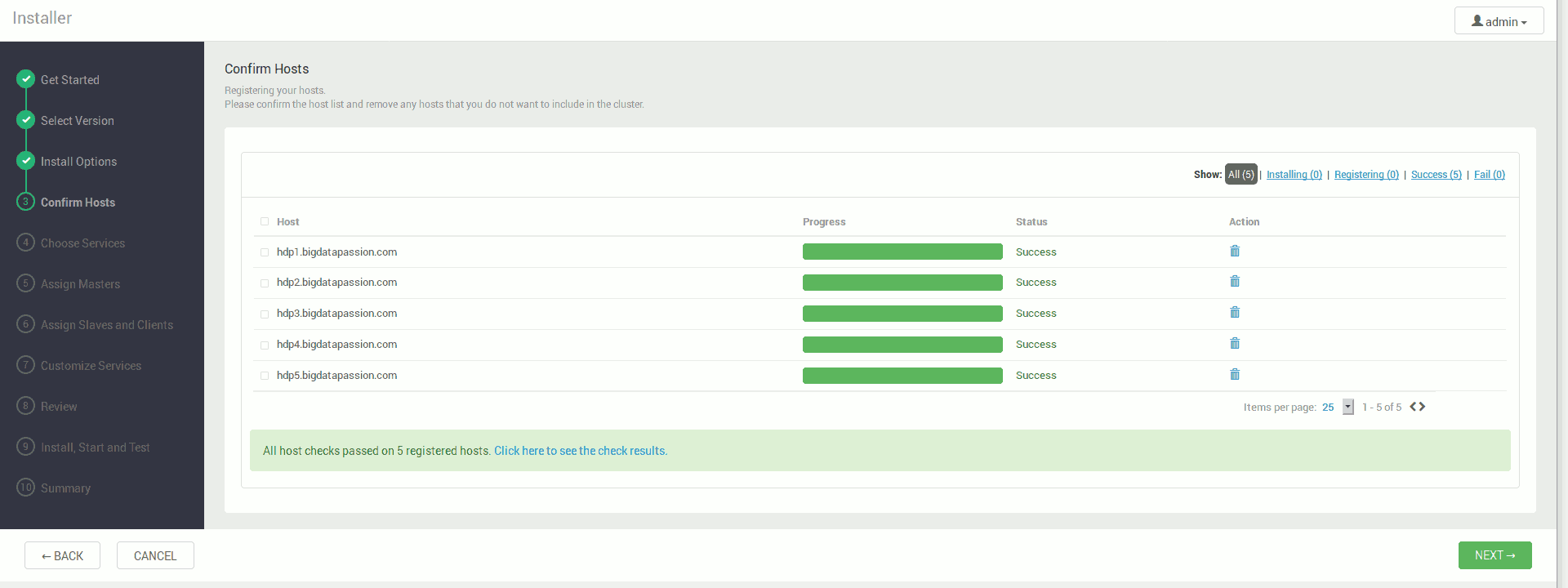
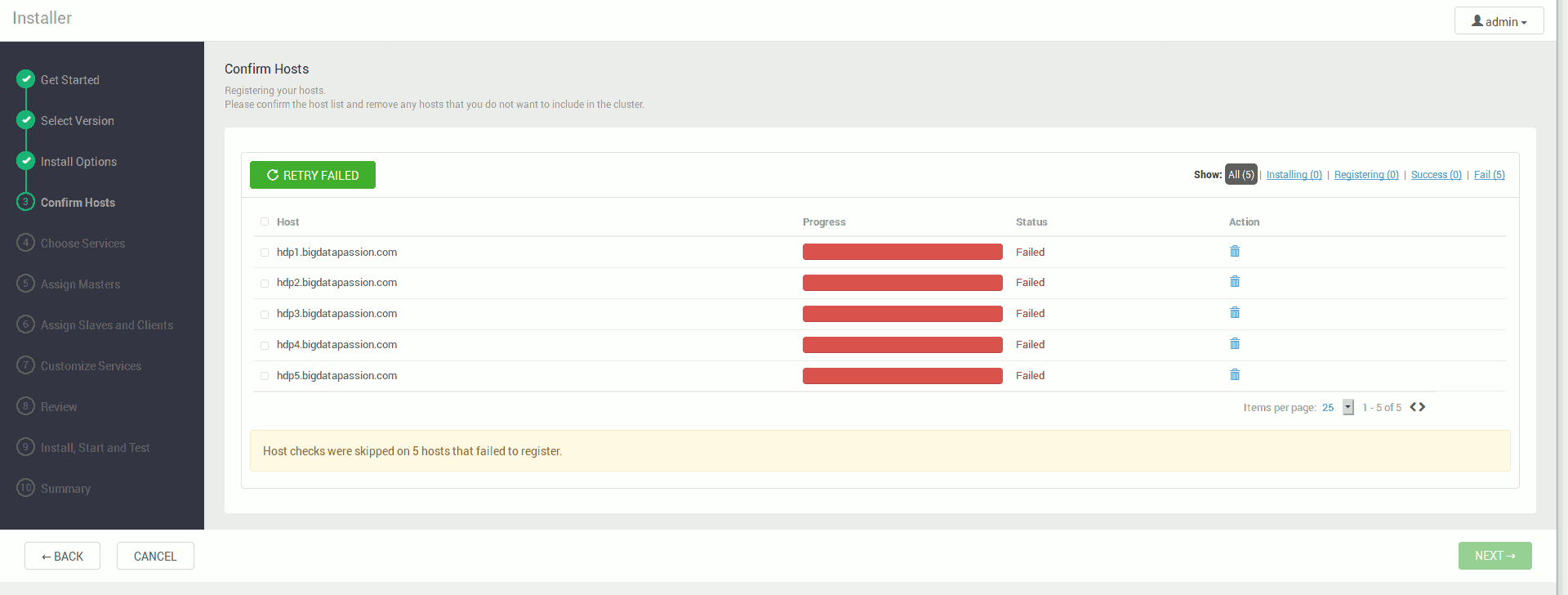
Jeśli jednak mamy informację o ostrzeżeniach na końcu instalacji agentów lub błędach podczas instalacji, należy przejrzeć ich listę i rozwiązać problemy
Następnie wybieramy narzędzia które chcemy zainstalować (ilość i rodzaj według uznania, np. HDFS, MapReduce2, Tez, Hive, Pig, HBase, Oozie, Flume, Ambari Metrics)
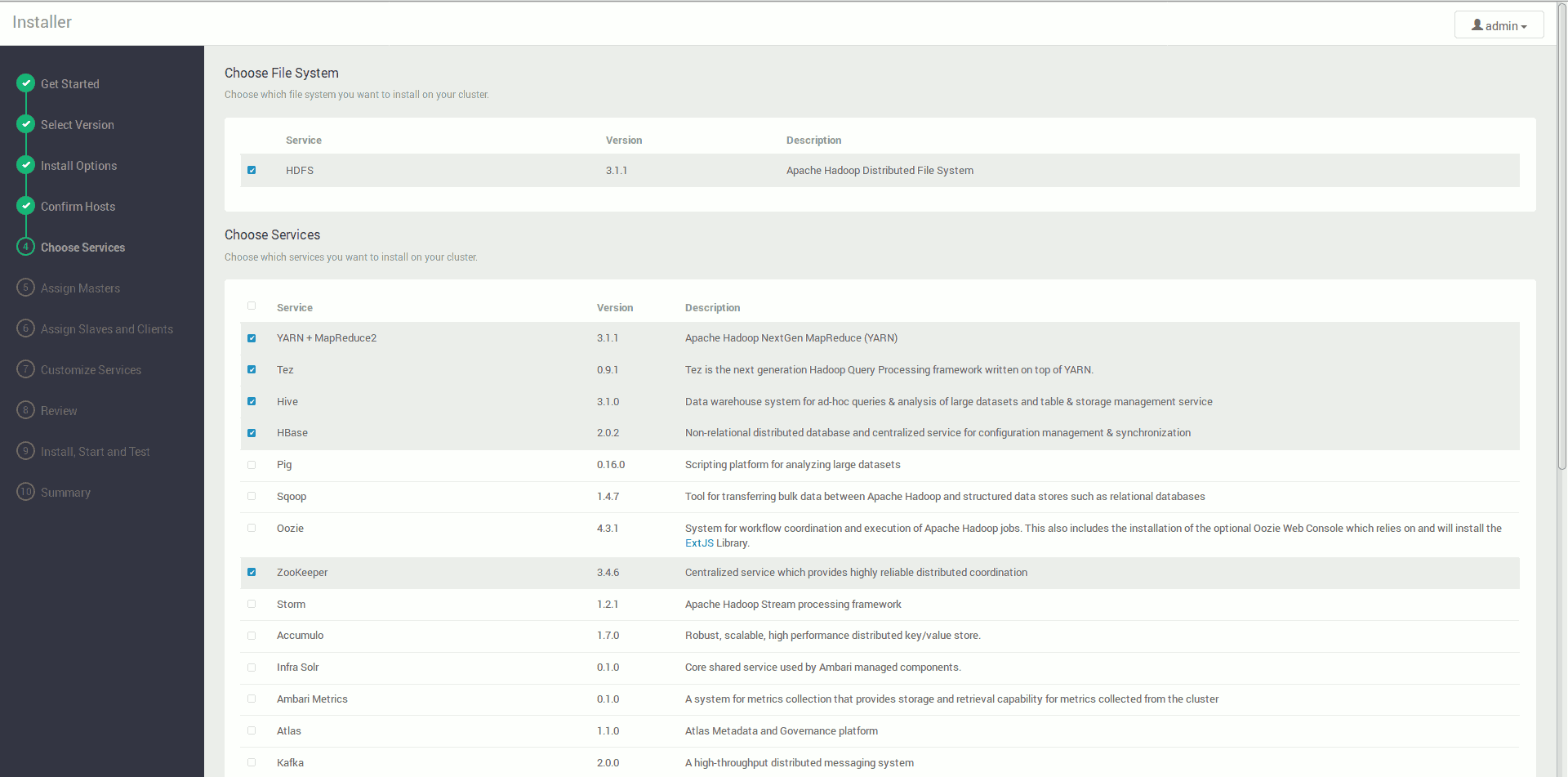
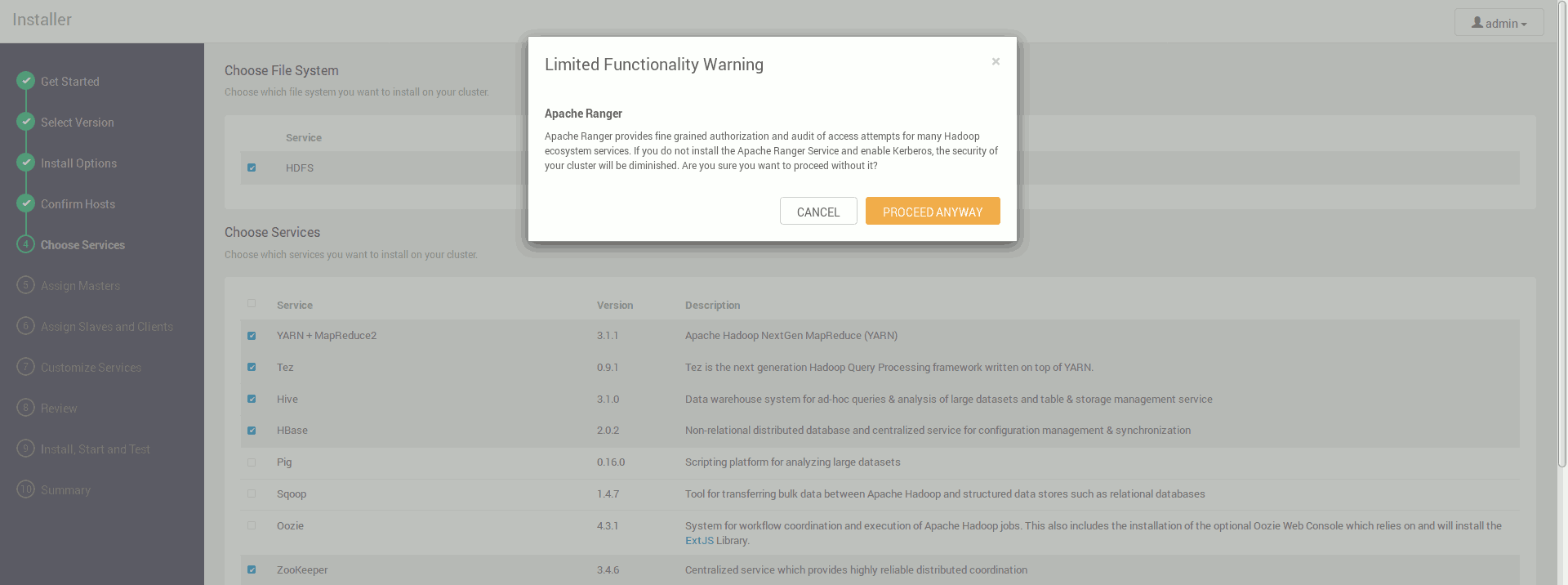
Niektóre narzędzia są połączone na tyle silnie, że Ambari może nam zasugerować konieczność instalacji czegoś dodatkowo
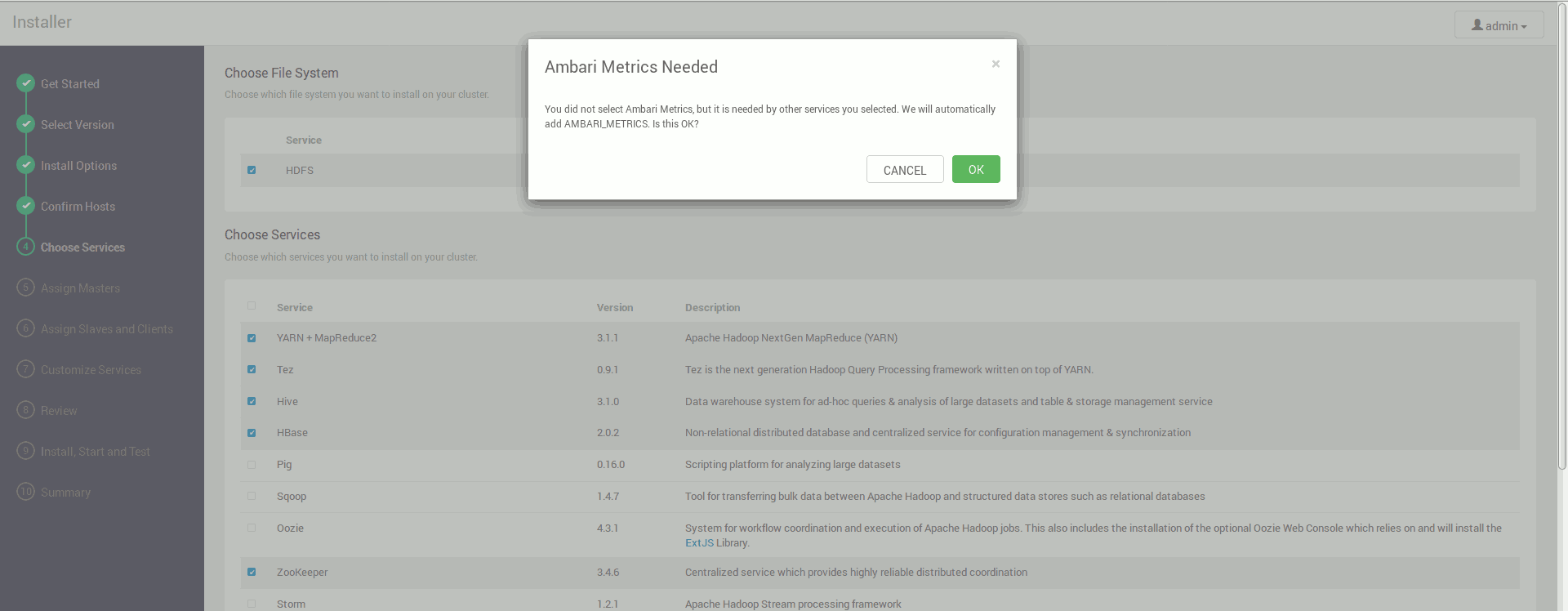
Ambari będzie także proponować nam instalację narzędzi które twórcy uznali za ważne a my ich samodzielnie nie wybraliśmy
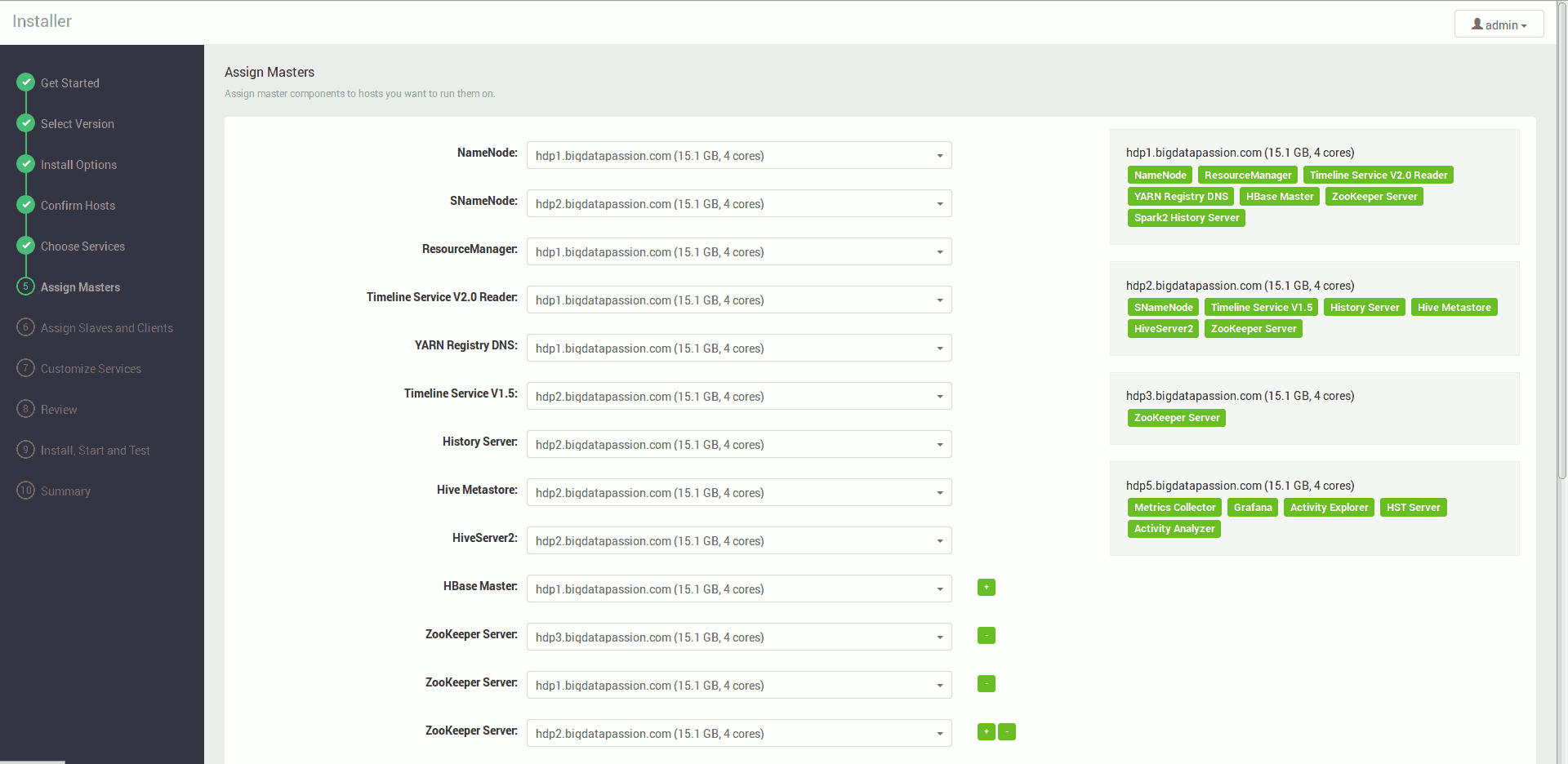
Wskazujemy na których maszynach mają być zainstalowane usługi zarządzające (Masters) (można zostawić na początek proponowane rozmieszczenie, tematowi jak rozmieszczać usługi przyjrzymy się w innym wpisie)
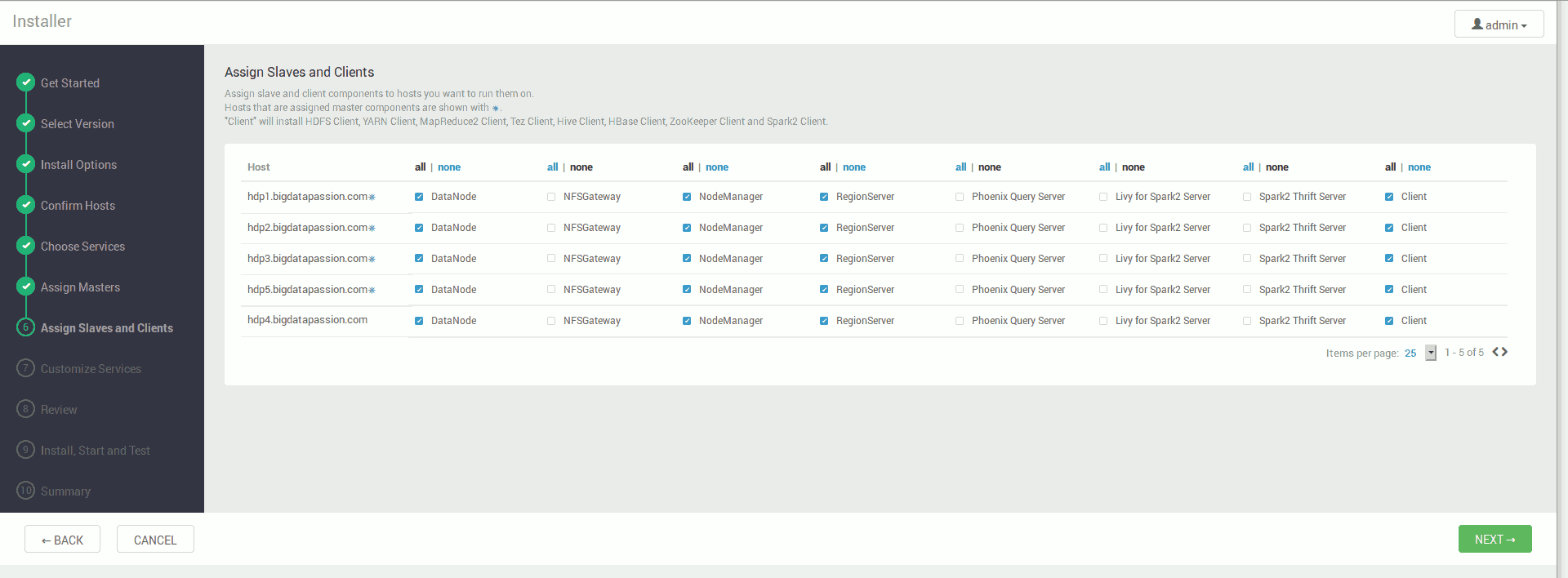
oraz usługi robocze (Slaves) (dla naszego testowego środowiska wybieramy wszystkie maszyny dla każdej z usług)
Konfigurujemy nasze serwisy, pola wymagane są na czerwono (najczęściej konieczność ustawienia hasła do bazy danych), pozostałe ustawienia na ten moment możemy pozostawić w ich wartościach domyślnych
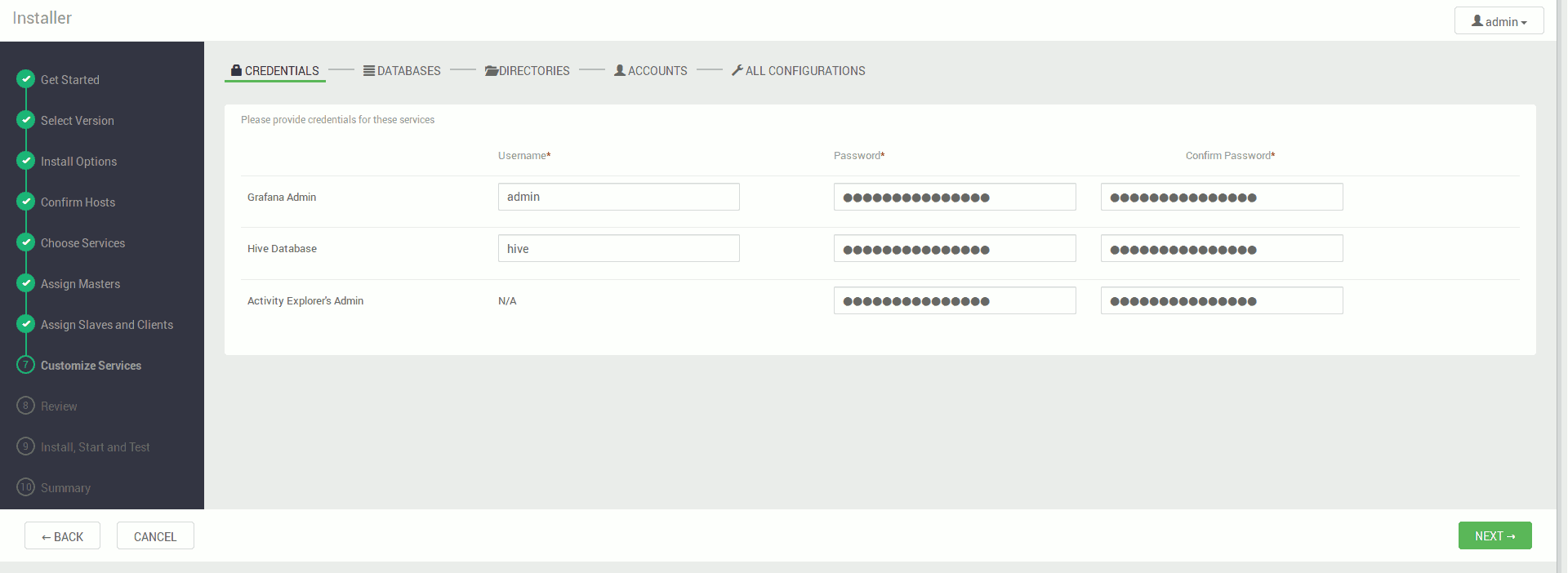
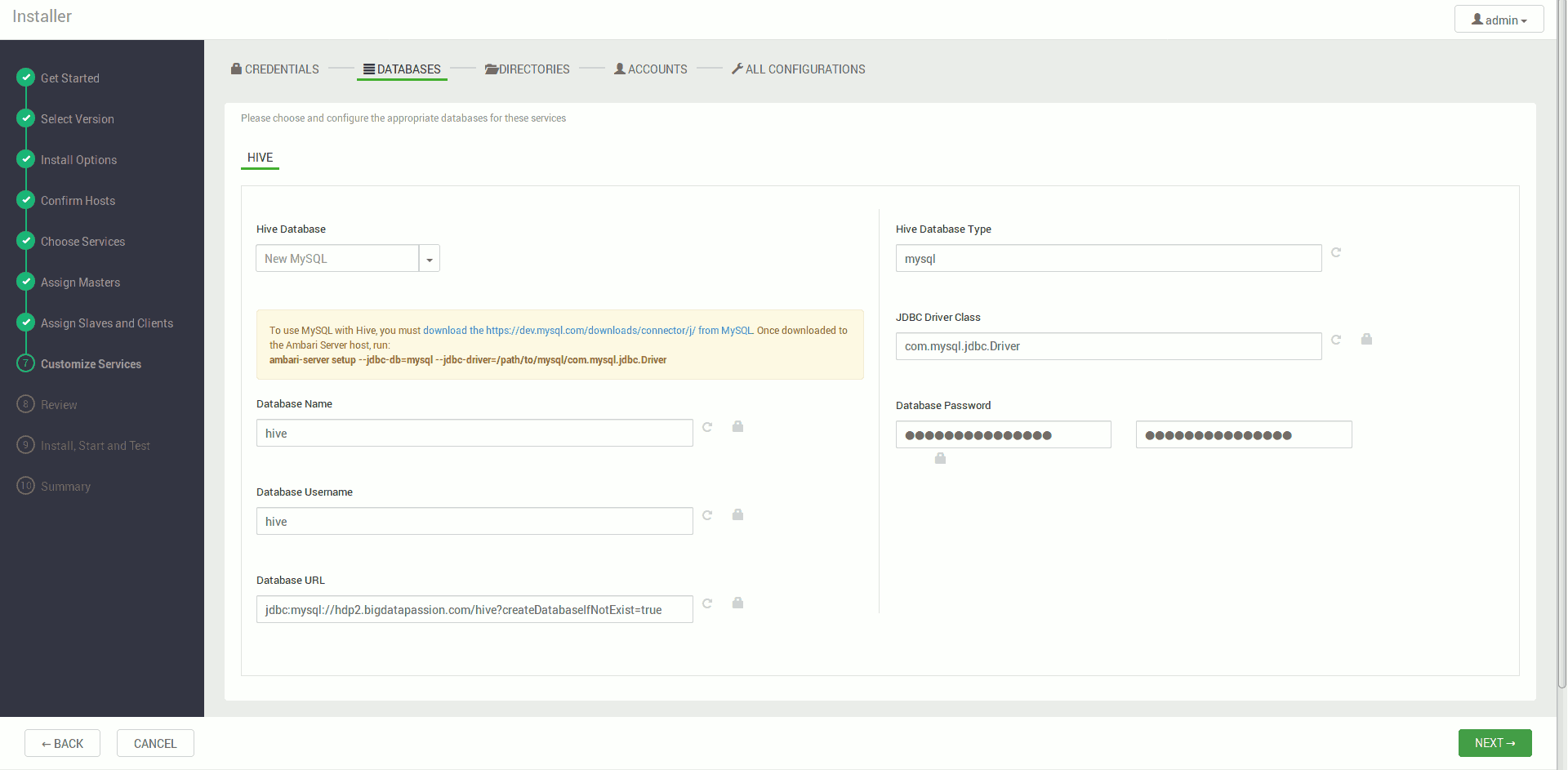
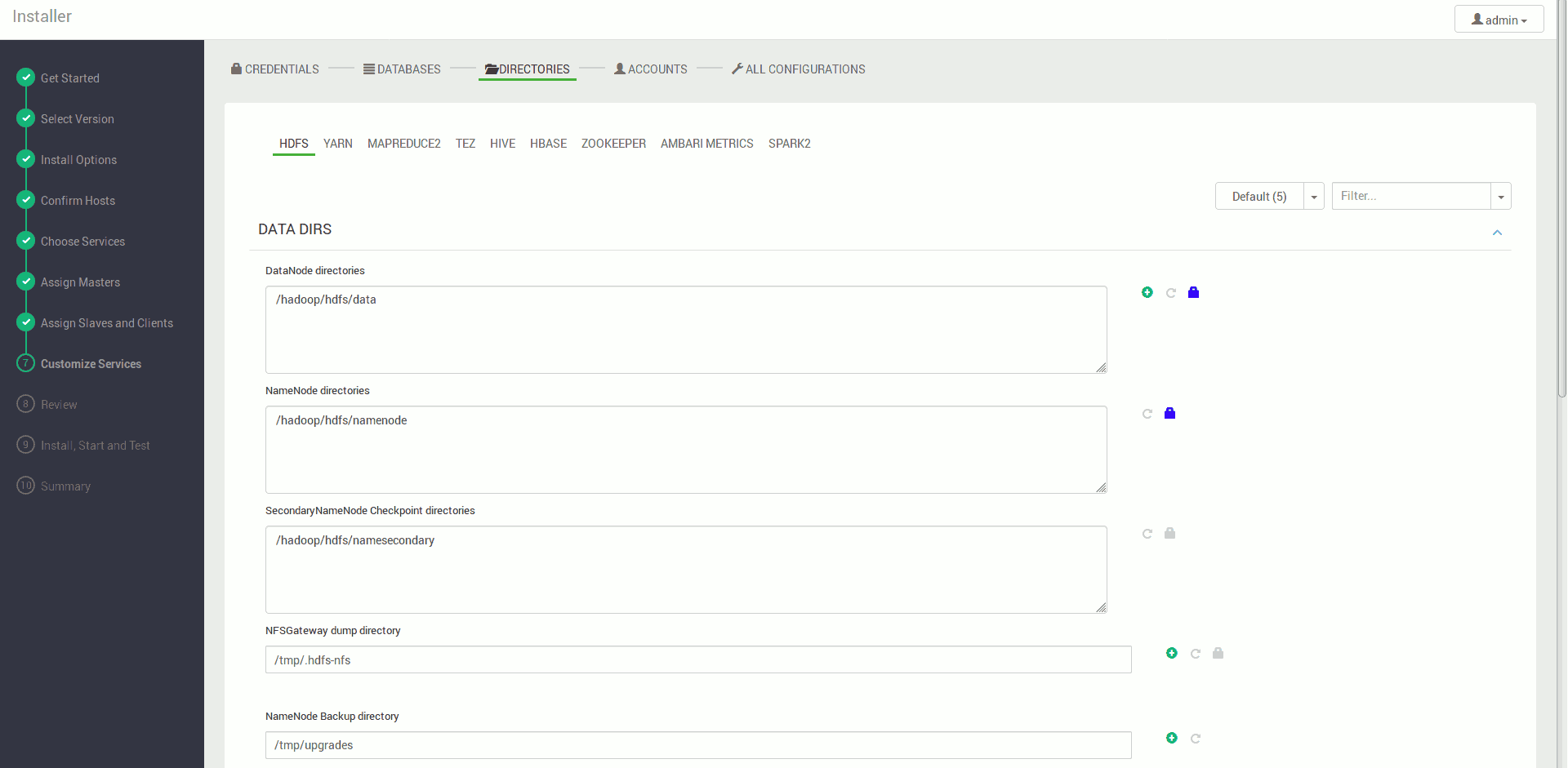
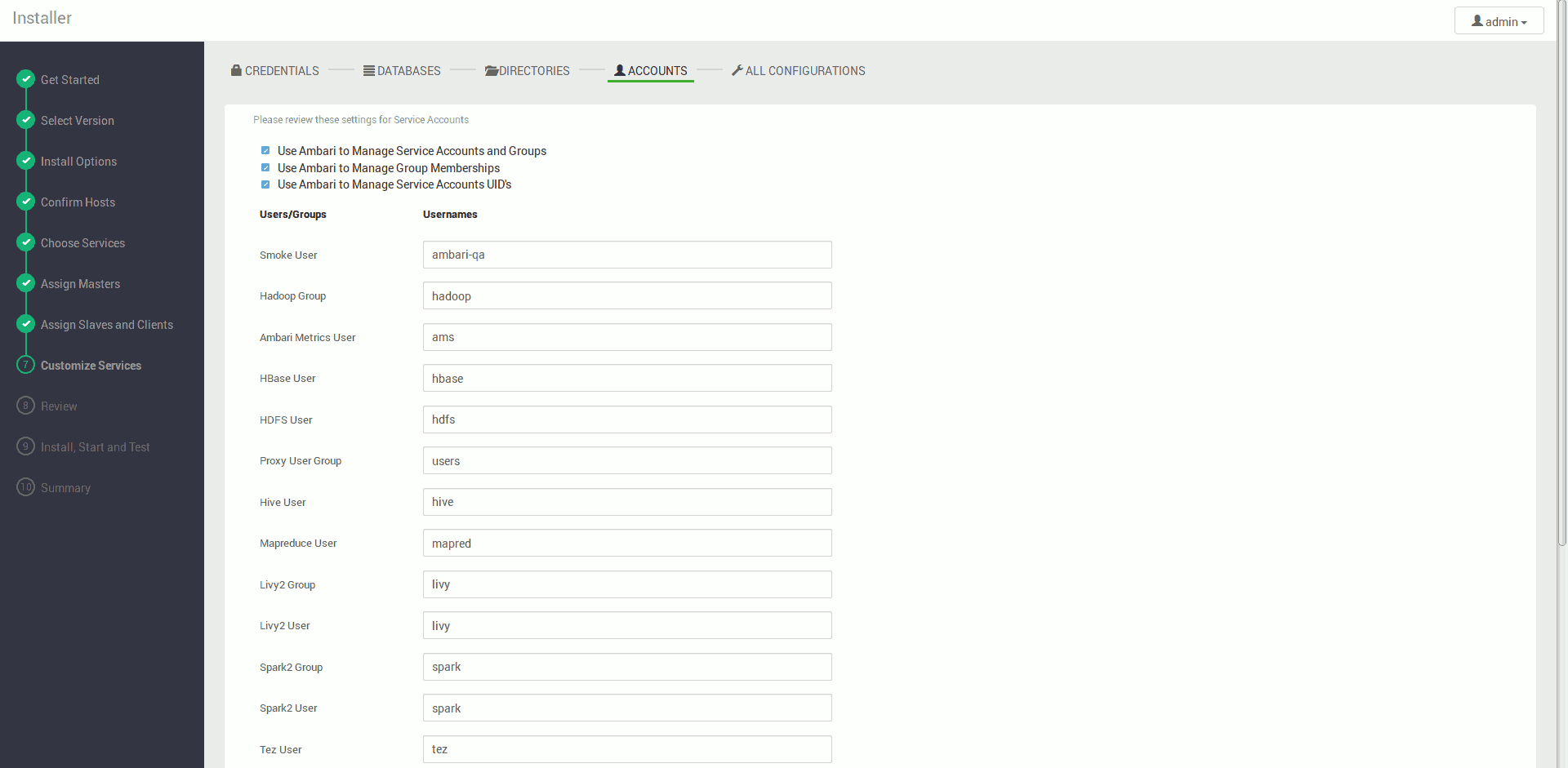
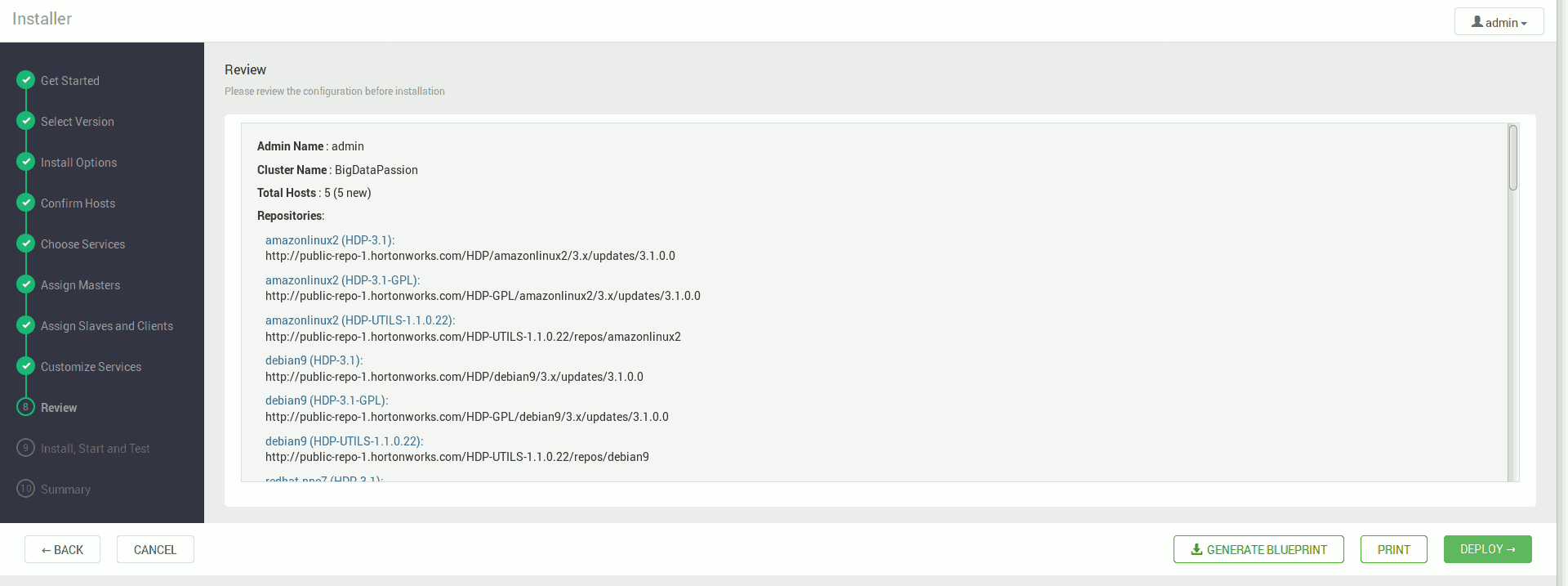
Akceptujemy ostrzeżenia i dostajemy podsumowanie instalacji
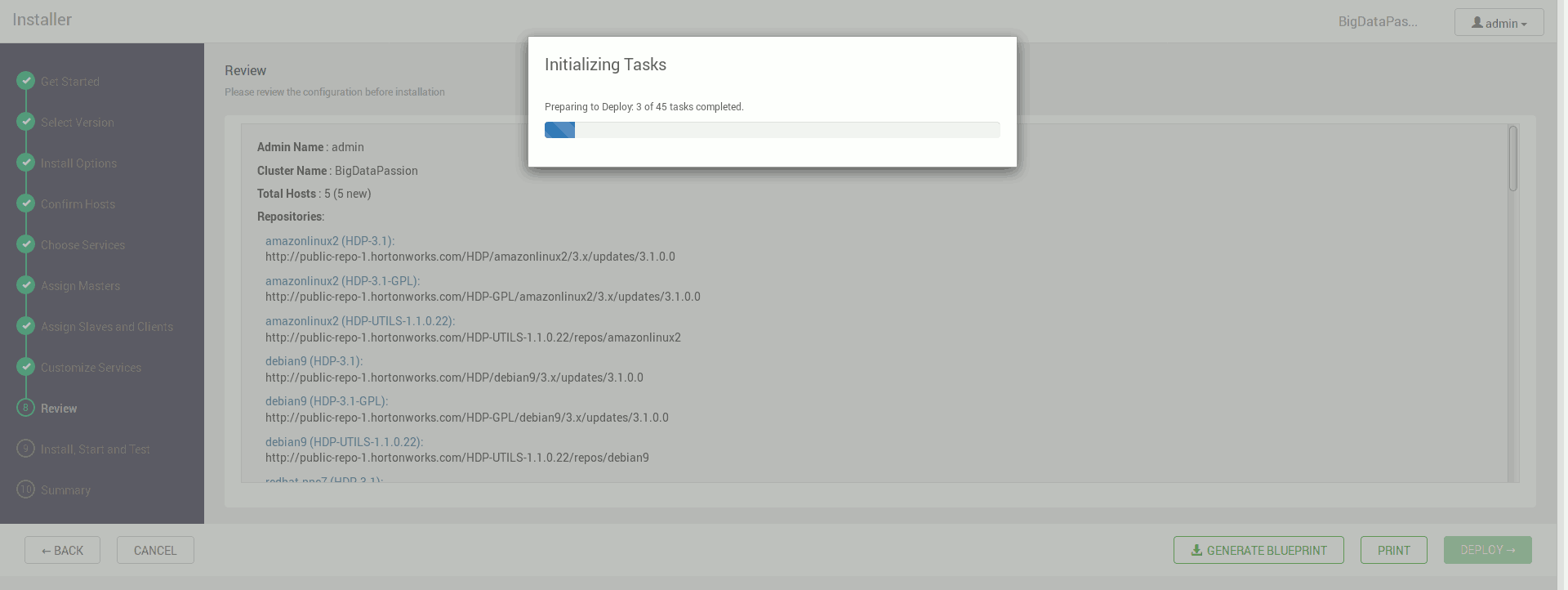
Na koniec Ambari zaczyna instalować wszystkie usługi zgodnie z naszymi wytycznymi
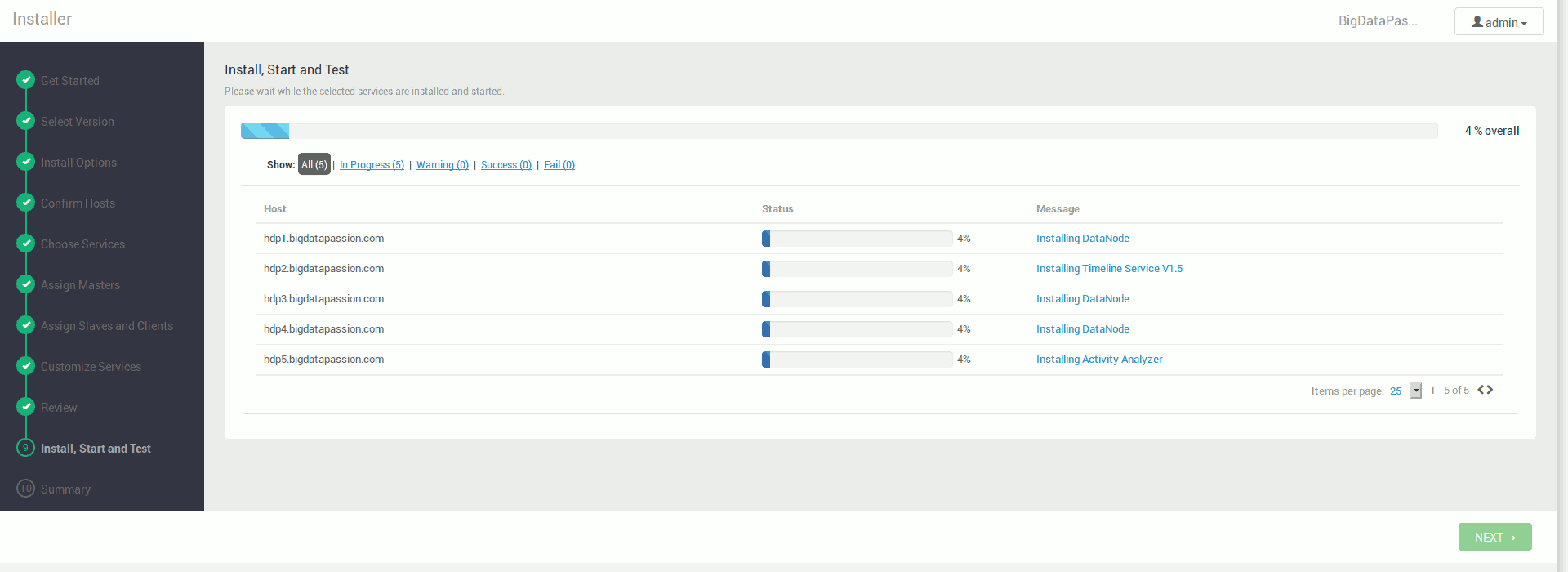
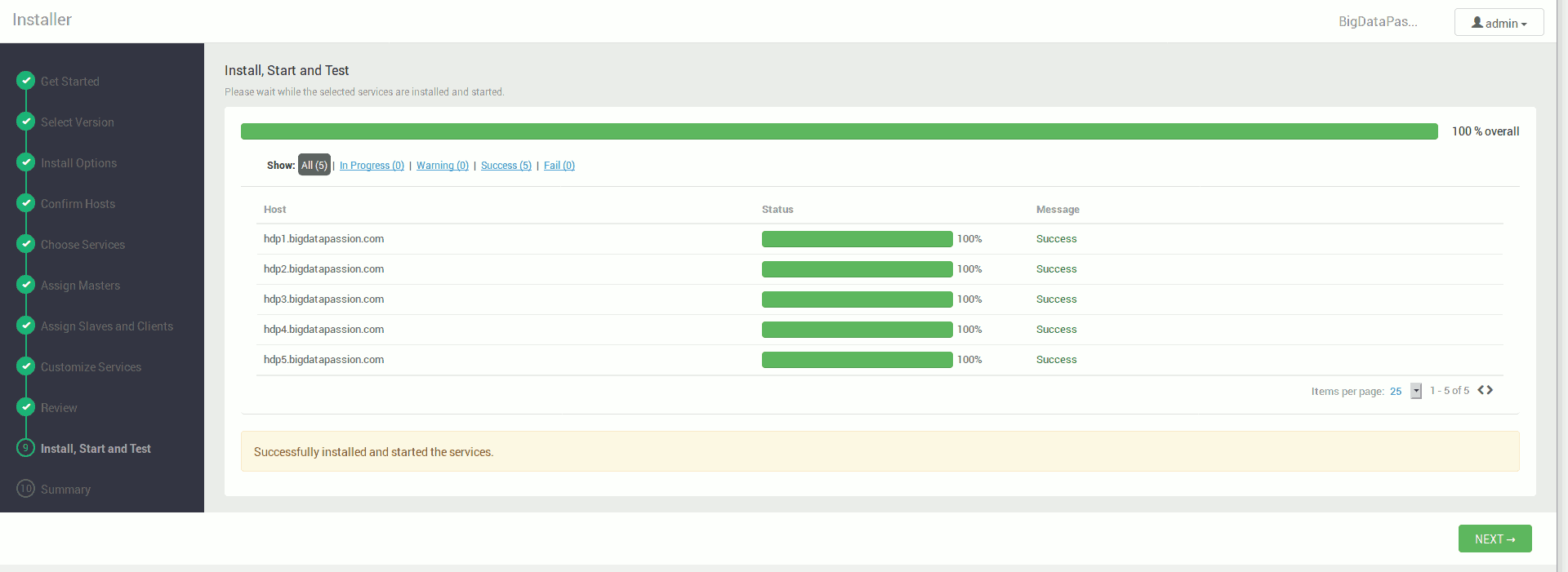
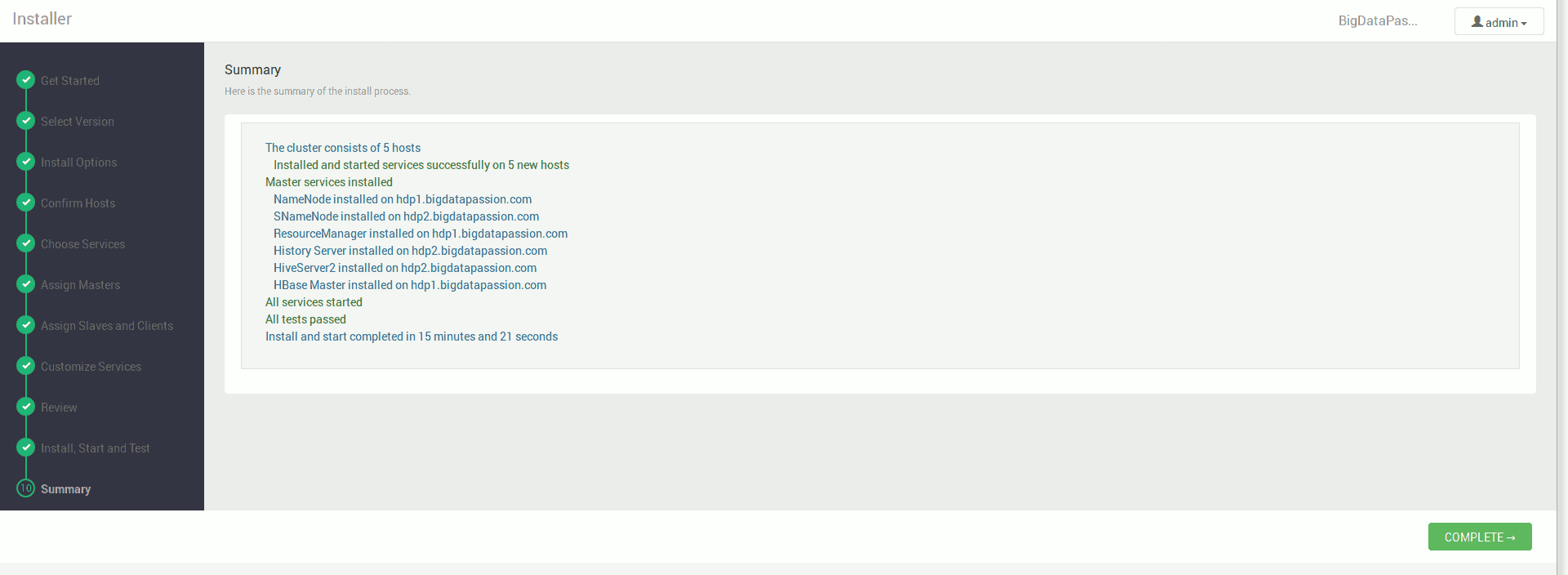
Po zakończonej instalacji możemy korzystać już w pełni wdrożonego klastra.
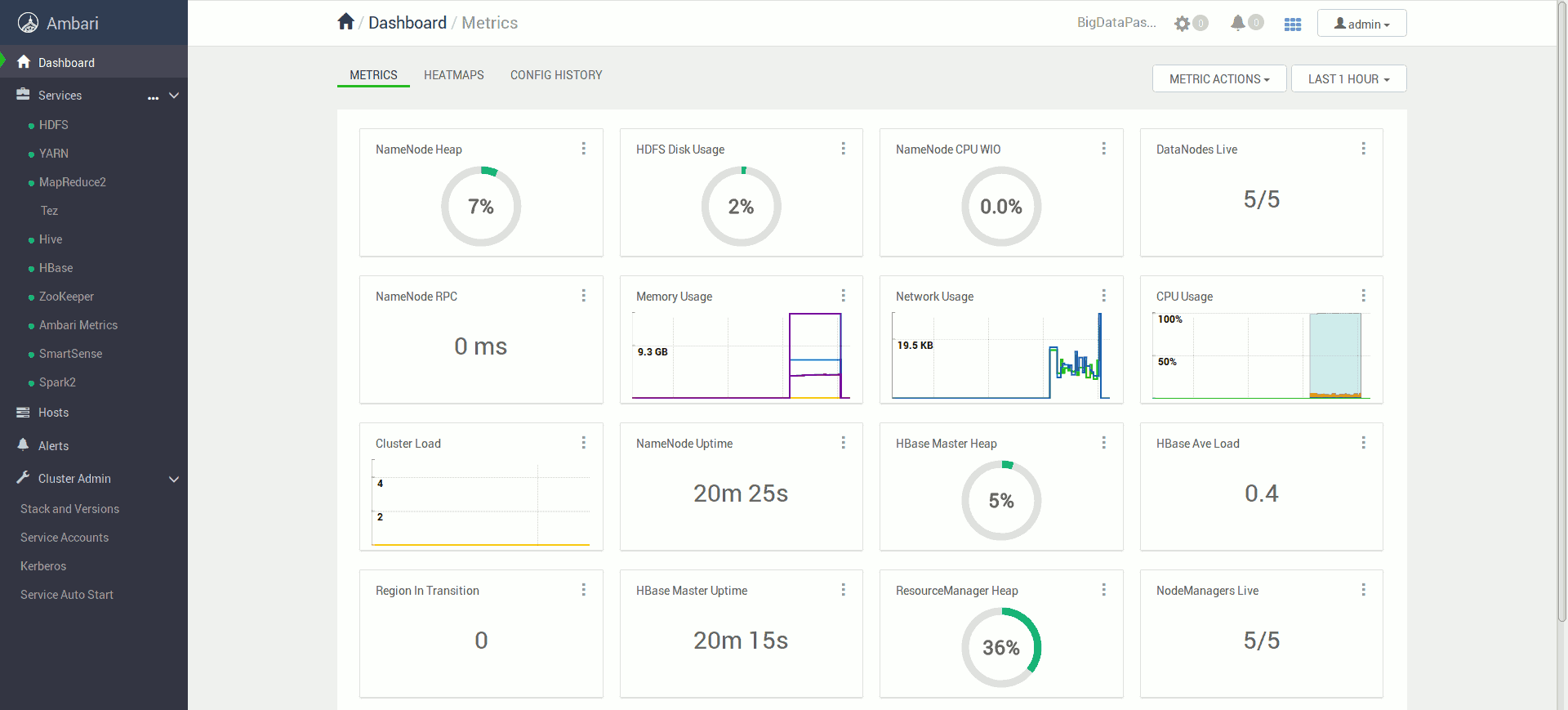
Możliwe problemy
Gdyby w trakcie instalacji wystąpiły jakieś błędy podczas uruchamiania usług, możemy spróbować zatrzymać wszystkie serwisy a następnie ponownie je włączyć. W tym celu w lewym pasku serwisów w menu Actions wybieramy Stop All a następnie Start All.
W przypadku niektórych wersji systemu CentOS lub Red Hat konieczna może okazać się ta porada związana z brakiem biblioteki libtirpc-devel.




